- Research
- Open access
- Published:
Incorporating prior knowledge induced from stochastic differential equations in the classification of stochastic observations
EURASIP Journal on Bioinformatics and Systems Biology volume 2016, Article number: 2 (2016)
Abstract
In classification, prior knowledge is incorporated in a Bayesian framework by assuming that the feature-label distribution belongs to an uncertainty class of feature-label distributions governed by a prior distribution. A posterior distribution is then derived from the prior and the sample data. An optimal Bayesian classifier (OBC) minimizes the expected misclassification error relative to the posterior distribution. From an application perspective, prior construction is critical. The prior distribution is formed by mapping a set of mathematical relations among the features and labels, the prior knowledge, into a distribution governing the probability mass across the uncertainty class. In this paper, we consider prior knowledge in the form of stochastic differential equations (SDEs). We consider a vector SDE in integral form involving a drift vector and dispersion matrix. Having constructed the prior, we develop the optimal Bayesian classifier between two models and examine, via synthetic experiments, the effects of uncertainty in the drift vector and dispersion matrix. We apply the theory to a set of SDEs for the purpose of differentiating the evolutionary history between two species.
1 Introduction
A purely data-driven classifier design with small samples encounters a fundamental conundrum: since the error rate of a classifier quantifies its predictive accuracy, the salient epistemic attribute of any classifier and re-sampling strategies such as cross-validation and bootstrap is generally very inaccurate on small samples due to excessive variance and lack of regression with the true error [1]. The inability to satisfactorily estimate the error with model-free methods with small samples implies that classifier error estimation is virtually impossible without the use of prior information. Prior knowledge can be incorporated in a Bayesian framework by assuming that the feature-label distribution belongs to an uncertainty class of feature-label distributions governed by a prior distribution [2, 3]. Given the latter, in conjunction with sample data, one can optimally estimate the error of any classifier, relative to the mean square error (MSE) between the true and estimated errors, where expectations are taken with respect to a posterior distribution derived from the prior distribution and the data [4, 5]. Hence, optimality is with respect to our prior knowledge and the data. Furthermore, one can derive an optimal classifier relative to the expected error of the classifier over the posterior distribution, this being called the optimal Bayesian classifier (OBC) [6, 7]. Closed-form solutions have been developed for multinomial and Gaussian models. In other situations, Markov Chain Monte Carlo (MCMC) methods can be used [8].
Having developed the statistical theory, one is confronted with an engineering problem: transform scientific knowledge given in some mathematical form into a prior distribution. Intuitively, given a set of mathematical relations among the features and labels, these relations constrain the uncertainty class of feature-label distributions that could potentially govern the classification and the relative strengths of the relations can be transformed so as to determine the probability mass of the prior distribution. For instance, in phenotype classification based on gene expression, genetic regulatory pathways constitute graphical prior knowledge and this prior knowledge can be employed to formulate a prior distribution governing the uncertainty class of feature-label distributions [9, 10]. Another genomic application involves using prior knowledge concerning RNA-seq data to form sequence-based classifiers [8].
From a general perspective, when using Bayesian methods, prior construction constitutes the highest hurdle. A half century ago, E. T. Jaynes remarked,
Bayesian methods, for all their advantages, will not be entirely satisfactory until we face the problem of finding the prior probability squarely [11].
The aim of this paper is to utilize prior knowledge in the form of stochastic differential equations (SDEs) to classify time-series data. Although we will confine ourselves to a Gaussian problem so that we can take advantage of existing closed-form OBC representations, one can envision further applications using MCMC methods. Hence, the approach taken in the present paper may lead to utilizing SDEs across a number of time-series classification problems, keeping in mind that SDEs play a major role in many disciplines including physics, biology, finance, and chemistry. Vector SDEs, our concern here, have various applications. Not only do they arise naturally in many systems with vector value states, but they also arise in many systems where the process is restricted to lie on certain manifolds [12].
In the stochastic setting, training data are collected over time processes. Given certain Gaussian assumptions, classification in the SDE setting takes the same form as ordinary classification in the Gaussian model and we can apply the optimal Bayesian classification theory once we have a prior distribution constructed in accordance with known stochastic equations. In this paper, we provide the mathematical framework to synthesize an OBC in the presence of prior knowledge induced in the form of SDEs governing the dynamics of the system. We consider a vector SDE in integral form involving a drift vector and dispersion matrix, develop the OBC between two models, and examine via synthetic experiments the effects of uncertainty in the drift vector and dispersion matrix.
We compare the performance of the OBC with quadratic discriminant analysis (QDA), a classical approach to building classifiers in the Gaussian model (see Additional file 2: Section I for definition of QDA). Such comparisons are useful because, even though the OBC is optimal given the uncertainty, its optimality is on average across the uncertainty class, so that its performance advantage varies for different feature-label distributions in the uncertainty class (and can be disadvantageous for some distributions, although these will have small probability mass in the posterior distribution). Comparison to QDA is instructive because, as we will explain in the next section, QDA is a sample-based approximation to the optimal classifier for the true feature-label distribution. In addition to synthetic experiments, we apply optimal Bayesian classification using a form of the Ornstein-Uhlenbeck process that has been employed for modeling the evolutionary change of species; specifically, we use a set of SDEs to construct a classifier to differentiate the evolutionary history between two species.
2 Background
2.1 Classification
In a two-class classification, the population is characterized by a feature-label distribution F for a random pair (X,Y), where X is a vector of p features and Y is the binary label, 0 or 1, of the class containing X. The prior class probabilities are defined by c j =P(Y=j) and the class-conditional densities by p j (x)=p(x∣Y=j), for j=0,1. To avoid trivialities, we assume min{c 0,c 1}≠0. A classifier is a function ψ(X) assigning a binary label to each feature vector X. The error, ε[ψ], of ψ is the probability P(ψ(X)≠Y), which can be decomposed into ε=c 0 ε 0+c 1 ε 1, where ε j=P(ψ(X)=1−j|Y=j), for j=0,1. A classifier with minimum error among all classifiers is known as a Bayes classifier for F. The minimum error is called the Bayes error. Epistemologically, the error is the key issue since it quantifies the predictive capacity.
In practice, F is unknown and a classification rule ψ is used to design a classifier ψ n from a random sample S n ={(X 1,Y 1),(X 2,Y 2),…,(X n ,Y n )} of pairs drawn from F. If feature selection is involved, then it is part of the classification rule. Since the true classifier error ε[ ψ n ] depends on F, which is unknown, ε[ψ n ] is unknown. The true error must be estimated by an estimation rule, Ξ. Thus, the random sample S n yields a classifier ψ n =Ψ(S n ) and an error estimate \(\hat {\varepsilon } [\!\psi _{n}]=\Xi (S_{n})\) (see Additional file 2: Section II for more information).
When a large amount of data is available, the sample can be split into independent training and test sets, the classifier being designed on the training data and its error being estimated by the proportion of errors on the test data; however, when data are limited, the sample cannot be split without leaving too little data to design a good classifier. Hence, training and error estimation must take place on the same data set. As noted in Section 1, accurate error estimation is virtually impossible with small samples in the absence of distributional assumptions.
2.2 Optimal Bayesian classification
Distributional assumptions can be imposed by defining a prior distribution over an uncertainty class of feature-label distributions. This results in a Bayesian approach with the uncertainty class being given a prior distribution and the data being used to construct a posterior distribution.
Let Π 0 and Π 1 denote the class-0 and class-1 conditional distributions, respectively; let c be the probability of a point coming from Π 0 (the “mixing” probability); and let Π 0 and Π 1 be parameterized by θ 0 and θ 1, respectively. The overall model is parameterized by θ=(c,θ 0,θ 1) with prior distribution π(θ). Given a random sample, S n , a classifier ψ n is designed and we wish to minimize the MSE between its true error, ε, and an error estimate, \(\widehat {\varepsilon }\). The minimum mean square error (MMSE) error estimator is the expected true error, \(\widehat {\varepsilon }(\psi _{n},S_{n})=\mathrm {E}_{\theta }[\varepsilon (\psi _{n},\theta)|S_{n}]\). The expectation given the sample is over the posterior density of θ, denoted by π ∗(θ). Thus, we write the Bayesian MMSE error estimator as \(\widehat {\varepsilon }=\mathrm {E}_{\pi ^{\ast }}[\varepsilon ]\).
The Bayesian error estimate is not guaranteed to be the optimal error estimate for any particular feature-label distribution but optimal for a given sample, and assuming the parameterized model and prior probabilities, it is both optimal on average with respect to MSE and unbiased when averaged over all parameters and samples. To facilitate analytic representations, we assume c, θ 0, and θ 1 are all mutually independent prior to observing the data. Denote the marginal priors of c, θ 0, and θ 1 by π(c), π(θ 0), and π(θ 1), respectively, and suppose data are used to find each posterior, π ∗(c), π ∗(θ 0), and π ∗(θ 1), respectively. Independence is preserved, i.e., π ∗(c,θ 0,θ 1)=π ∗(c)π ∗(θ 0)π ∗(θ 1) [4].
If ψ n is a trained classifier given by ψ n (x)=0 if x∈R 0 and ψ n (x)=1 if x∈R 1, where R 0 and R 1 are measurable sets partitioning the sample space, then the Bayesian MMSE error estimator can be found from effective class-conditional densities, which are derived by taking the expectations of the individual class-conditional densities with respect to the posterior distribution,
Using these [6] (see Additional file 2: Section III for more information),
In the context of a prior distribution, an optimal Bayesian classifier, ψ OBC, is any classifier satisfying
for all \(\psi \in \mathcal {C}\), where \(\mathcal {C}\) is an arbitrary family of classifiers. Under the Bayesian framework, this is equivalent to minimizing the probability of error,
If \(\mathcal {C}\) is the set of all classifiers with measurable decision regions (which we will assume), then an optimal Bayesian classifier, ψ OBC, satisfying (3) for all \(\psi \in \mathcal {C}\) exists and is given pointwise by [6]
In many applications, especially in biomedicine, the sample S n is obtained by first deciding how many sample points will be taken from each class and then randomly sampling from each class separately, the resulting sample said to be “separately sampled.” With separate sampling, the data cannot be used to generate a posterior distribution for c, so that c must be known. Stratified sampling is a special case of separate sampling in which the sample is drawn so that the proportion of sample points from class 0 is equal to c. In such a case, there is no posterior \(\mathrm {E}_{\pi ^{\ast }\phantom {\dot {i}\!}}[\!c]\) and \(\mathrm {E}_{\pi ^{\ast }\phantom {\dot {i}\!}}[\!c]\) is replaced by c in (5). We will utilize stratified sampling in our examples.
3 Binary classification of Gaussian processes
In this section, we frame the setting in which we are working and then define the problem of binary classification in the context of Gaussian processes. To begin with, a collection {X t :t∈T} of \(\mathbb {R}^{p}\)-valued random variables defined on a common probability space \((\Omega,\mathcal {F},P)\) indexed by a parameter \( t\in \mathbf {T}\subset \mathbb {R}\) (here assumed to be time) and \(\mathcal {F}\) being a σ-algebra of subsets of the sample space Ω (events) constitutes a stochastic process X with state space \(\mathbb {R} ^{p}\). Throughout this work, we consider \(\mathcal {F}\) as the σ-algebra of Borel subsets of \(\mathbb {R}^{p}\). A stochastic process X is adapted to an increasing family of σ-algebra \(\{\mathcal {F}_{t}:t\geq 0\}\) (a filtration) if for each t≥0, X t is \(\mathcal {F}_{t}\)-measurable.
We study classification in the context of multivariate Gaussian processes (see Additional file 2: Section IV for a review of literature pertaining to classification of stochastic processes). Consider the p-dimensional column random vectors \(\mathbf {X}_{t_{1}}\), \(\mathbf {X}_{t_{2}}\),...., \(\mathbf {X}_{t_{N}}\). A random process X is a multivariate Gaussian process if any finite-dimensional vector \(\left [\mathbf {X}_{t_{1}}^{T},\mathbf {X}_{t_{2}}^{T},...,\mathbf {X}_{t_{N}}^{T}\right ]^{T} \) possesses a multivariate normal distribution \(\mathcal {N}\left (\boldsymbol {\mu }_{\mathbf {t}_{N}},\boldsymbol {\Sigma }_{\mathbf {t}_{N}}\right)\), where
with \(\boldsymbol {\mu }_{{t}_{i}\phantom {\dot {i}\!}}=E[\mathbf {X}_{t_{i}\phantom {\dot {i}\!}}]\), and \(\boldsymbol { \Sigma }_{\mathbf {t}_{N}\phantom {\dot {i}\!}}\) is the N p×N p covariance matrix dependent on t N =[t 1,t 2,...,t N ]T and structured as
where
We refer to t N as the observation time vector. For any fixed ω∈Ω, a sample path is a collection {X t (ω):t∈t}. We denote a realization of X at sample path ω and time vector t N by \( \mathbf {x}_{\mathbf {t}_{N}\phantom {\dot {i}\!}}(\omega)\).
We consider a general framework, referred to as binary classification of Gaussian processes (BCGP). Consider two independent multivariate Gaussian processes X 0 and X 1, where for any t N , X 0 and X 1 possess mean and covariance \(\boldsymbol {\mu }_{\mathbf {t}_{N}}^{0}\) and \(\boldsymbol {\Sigma }_{\mathbf {t}_{N}}^{0}\), and \(\boldsymbol {\mu }_{\mathbf {t}_{N}}^{1}\) and \(\boldsymbol {\Sigma }_{\mathbf {t}_{N}}^{1}\), respectively. For y=0,1, \( \boldsymbol {\mu }_{\mathbf {t}_{N}}^{y}\) is defined similarly to (6) with \(\boldsymbol {\mu }_{{t}_{i}}^{y}=E\left [\mathbf {X}_{t_{i}}^{y}\right ]\) and \(\boldsymbol {\Sigma }_{\mathbf {t}_{N}}^{y}\) is defined similarly to (7) with
Let \(\mathbf {S}_{\mathbf {t}_{N}}^{y}\) denote a set of n y sample paths from process X y at t N ,
We assume that t N is the same for both classes. Let \(\mathbf {X}_{\mathbf {t}_{N}}^{y}(\omega _{s})\) denote a future test sample path observed on the same observation time vector as the training sample paths, where y∈{0,1} indicates the label of the class-conditional process the sample path is coming from, either X 0 or X 1. Note that, as compared with the classical probabilistic definition of classification where the sample points are observations of p-dimension, here we define stochastic-process classification in connection with a set of sample paths, which can be considered as observations of Np dimension. A classification problem arises from the fact that the experimenter is blind to the class label of \(\mathbf {X}_{\mathbf {t}_{N}}^{y}(\omega _{s})\), i.e., to y, and desires a discriminant \(\psi _{\mathbf {t}_{N}\phantom {\dot {i}\!}}(.)\) such that
Other types of classification could be defined. For example, one might be interested in classifying a test sample path \(\mathbf {x}_{\mathbf {t}_{N+M}}^{y}(\omega _{s})\) where the observation time vector of the test sample path is obtained by augmenting t N by another vector [t N+1,t N+2,...,t N+M ], where M is a positive integer. In this case, the time of observation for the future sample path is extended. Similarly, one may define problems where the future time of observation is shrunken to a subset of time points in t N or problems where the future observation time vector is a set of time points totally or partially different from time points in t N . Throughout this work, we are mainly concerned with solving the classification problem as defined in (11), which we refer to as the standard type, and we discuss the feasibility of solving other cases when possible.
3.1 General presentation of stochastic differential equations (SDEs)
To define SDEs, we consider a diffusion process, the most fundamental being the Wiener process. For a general definition of a q-dimensional Wiener process, see the Appendix. Let W={W t :t≥0} be a q-dimensional Wiener process. For each sample path and for 0≤t 0≤t≤T, we consider a vector SDE in the integral form as follows:
where \(\mathbf {f}:[\!0,T]\times \Omega \rightarrow \mathbb {R}^{p}\) (the p-dimensional drift vector) and \(\mathbf {G}:[\!0,T]\times \Omega \rightarrow \mathbb {R}^{p\times q}\) (the p×q dispersion matrix). The first integral in (12) is an ordinary Lebesgue integral, and throughout this work, we assume an Itô integration for the second integral. With slightly more work, the results can be extended to Stratonovich integration. Let \(\mathcal {L}\) be the σ-algebra of Lebesgue subsets of \(\mathbb {R}\). A function h(t,ω) defined on a probability space \((\Omega,\mathcal {F},P)\) belongs to \(\mathcal {L}_{T}^{\omega }\) if it is jointly \(\mathcal {L}\times \mathcal {F}\) measurable, h(t,.) is \(\mathcal {F}_{t}\)-measurable for each t∈[ 0,T], and with probability 1, \({\int _{0}^{T}}h(s,\omega)^{2}ds<\infty \). Let f i and g i,j denote the components of f and G, respectively. If we assume X 0(ω) is \(\mathcal {F}_{0}\)-measurable and if \(\sqrt {|f^{i}|}\in \mathcal {L}_{T}^{\omega }\) and \(g^{i,j}\in \mathcal {L}_{T}^{\omega }\), then each component of the p-dimensional process X t (ω) is \(\mathcal {F}_{t}\)-measurable [12]. The \(\mathcal {F}_{t}\)-measurability of X t (ω) along with the martingale property of W indicates “nonanticipativeness” of X t (ω) in general.
The integral Eq. (12) is commonly written in a symbolic form as
which is the representation of a vector SDE.
4 SDE prior knowledge in the BCGP model
Prior knowledge in the form of a set of stochastic differential equations constrains the possible behavior of the dynamical system to an uncertainty class. If such prior knowledge is available, then it can be used in the BCGP model to improve classification performance. The core underlying assumption of the BCGP model is that the data are generated from two Gaussian processes for which binary classification is desired. In this regard, we define valid prior knowledge (in the form of SDEs) as a set of SDEs with a unique solution that does not contradict the Gaussianity assumption of the dynamics of the model. For nonlinear f(t,X t ) and G(t,X t ) (w.r.t. to state X t ), the solution of SDE (13) is generally a non-Gaussian process. Fortunately, under a wide class of linear functions, the SDE solutions are Gaussian. To wit, the SDEs become valid prior knowledge for each class-conditional process defined in the BCGP model. Henceforth, we focus on this type of SDE.
For class label y=0,1, the linear classes of SDEs that we consider are defined by replacing
in (13) with A y(t) (a p×p matrix), a y(t) (a p×1 vector), and B y(t) (a p×q matrix), these being measurable and bounded on [ t 0,T]. This results in
This initial value problem has a unique solution that is a Gaussian stochastic process if and only if the initial conditions c y are constant or normally distributed (Theorem 8.2.10 [13]). Note that in this model, G y(t,X t ) (i.e. B y(t)) is independent of ω. Under this model, it can be shown that the mean (at a time index t i ) and the covariance matrix (at t i and t j ) of the Gaussian process \(\mathbf {X}_{t}^{y}\) are given by [13]
and
where t 0≤t i ≤t j ≤T and Φ y(t i ) is the fundamental matrix of the deterministic equation
4.1 SDEs as perfect representatives for the dynamics of class-conditional processes
If the SDE model presented in (15) could perfectly represent the dynamics of the underlying stochastic processes of the BCGP model, then there would be no need for training sample paths. To see this, note that in this case \({\boldsymbol {\mu }}_{t}^{y}\) and \({\boldsymbol {\Sigma }} _{t_{i},t_{j}}^{y}\) defined in (6) and (7) are obtained by
where
and
where \({\mathbf {m}_{t_{i}}^{y\,T}}\) and \(\boldsymbol {\Psi }_{{t}_{i},{t} _{j}}^{y}\) are obtained from (16) and (17), respectively. Therefore, one can obtain the exact (or at least approximately exact) values of the means and auto-covariances used to characterize the Gaussian processes involved in the BCGP model. To obtain \({\mathbf {m}_{t_{i}}^{y}}\) and \(\boldsymbol {\Psi }_{{t}_{i},{t}_{j}}^{y}\), two approaches can be taken. First, one may analytically solve (18) where possible and then use numerical methods to evaluate the integrations presented in (16) and (17). For example, if A y(t)=A y, i.e., being independent of t, the solution of (18) is given by a matrix exponential as
which can be used in (16) and (17). In general, where one may not be able to analytically solve (18), numerical methods such as the Euler-Maruyama scheme [14] can be used to directly solve for \( \mathbf {X}_{t}^{y}(\omega)\) and obtain
where \(\mathbf {x}_{\mathbf {t}_{N}}^{y,\text {SDE}}(\omega _{i}),i=1,2,...,l^{y}\), are the generated sample paths obtained from solving SDEs. Since there is no restriction on generating an arbitrary number of sample paths from \(\mathbf {X}_{t}^{y}(\omega)\), one can take l y>>N p to have a positive definite \( \hat {{\boldsymbol {\Psi }}}_{\mathbf {t}_{N}}^{y}\) and, at the same time, obtain an accurate estimate of the actual values of \({\mathbf {m}}_{\mathbf {t}_{N}}^{y}\) and \({{\boldsymbol {\Psi }}}_{\mathbf {t}_{N}}^{y}\). In this approach, the knowledge of (16) and (17) is used in the existence of the limits \({\lim }_{l^{y}\rightarrow \infty }\,\hat {\mathbf {m}}_{\mathbf {t}_{N}}^{y}\) and \({\lim }_{l^{y}\rightarrow \infty }\,\hat {{\boldsymbol {\Psi }}}_{\mathbf {t}_{N}}^{y}\), i.e., justifies generating more sample paths as \({\lim }_{l^{y}\rightarrow \infty }\,\hat {\mathbf {m}}_{\mathbf {t}_{N}}^{y}={\mathbf {m}}_{\mathbf {t}_{N}}^{y}\) and \({\lim }_{l^{y}\rightarrow \infty }\,\hat {{\boldsymbol {\Psi }}}_{\mathbf {t}_{N}}^{y}={{\boldsymbol {\Psi }}}_{\mathbf {t}_{N}}^{y}\).
In any case, we can assume exact (approximately exact) values of \(\mathbf {m}_{t_{i}}^{0}\), \(\mathbf {m}_{t_{i}}^{1}\), \({\boldsymbol {\Psi }}_{t_{i},t_{j}}^{0}\), and \({\boldsymbol {\Psi }}_{t_{i},t_{j}}^{1}\) are available. The optimal discriminant in this case is obtained by using the conventional quadratic discriminant analysis (QDA), which is now defined by using the following statistic in (11):
The use of (24) is justified by the fact that the BCGP classification reduces to differentiating independent observations of Np dimension generated from two multivariate Gaussian distributions. Therefore, taking the same set of machinery as in [15] results in (24). We restate that in this case where (19) holds, there is no need for utilizing the sample path measurements (training sample paths) in finding the discriminant (24). This is due to the fact that the statistical properties of a Gaussian process at t N are solely determined by \({\mathbf {m}}_{\mathbf {t}_{N}}^{y}\) and Ψ t N y and, as mentioned before, either closed-form solutions of these are available or they can be approximated element-wise with an arbitrary small error rate by generating a sufficiently large number of sample paths.
The optimal solution proposed in (24) is, in fact, a function of the observation time vector of future sample paths. Therefore, if a future sample point \(\mathbf {x}_{\mathbf {t}_{L}}^{y}(\omega _{s})\) is measured at an arbitrary time vector t L , which can be partially or totally different from t N , then the optimal discriminant \(\psi _{\mathbf {t}_{L}}\left (\mathbf {x}_{\mathbf {t}_{L}}^{y}(\omega _{s})\right)\) is obtained by determining the solution of SDEs at t L and replacing \({\mathbf {m}}_{\mathbf {t}_{N}}^{y}\) and \({\boldsymbol {\Psi }}_{\mathbf {t}_{N}}^{y}\) with \({\mathbf {m}}_{\mathbf {t}_{L}}^{y}\) and \({ \boldsymbol {\Psi }}_{\mathbf {t}_{L}}^{y}\), respectively, in (24).
4.2 SDEs as prior information for the dynamics of class-conditional processes
In practice, the SDEs usually do not provide complete description and are then viewed as prior knowledge concerning the underlying dynamics of the BCGP model. Since we assume that a Gaussian process governs both the dynamics of each class-conditional process (BCGP model in Section 3) and its corresponding set of SDEs (by using model (15)), incompleteness of the SDEs results from the fact that (19) does not necessarily hold. We make the following assumptions on the nature of the prior information to which the set of SDEs corresponding to each class give rise: (i) before observing the sample paths at an observation time vector, the SDEs characterize the only information that we have about the system and (ii) the statistical properties of all Gaussian processes that may generate the data are on average (over the parameter space) equivalent to the statistical properties determined from the SDEs. The latter statement will subsequently be formalized.
Assume that the parameters \(\boldsymbol {\mu }_{\mathbf {t}_{N}}^{y}\) and \(\boldsymbol {\Sigma }_{\mathbf {t}_{N}}^{y}\) defining the BCGP model constitute a realization of the random vector \(\mathbf {\theta }_{\mathbf {t}_{N}}^{y}=\left [\boldsymbol {\mu }_{\mathbf {t}_{N}}^{y},\boldsymbol {\Sigma }_{\mathbf {t}_{N}}^{y}\right ]\), where \(\mathbf {\theta }_{\mathbf {t}_{N}}^{y}\) has a prior distribution \(\pi (\mathbf {\theta }_{\mathbf {t}_{N}}^{y})\) parameterized by a set \(\left \{\breve {\mathbf {m}}_{\mathbf {t}_{N}}^{y},\breve {\boldsymbol {\Psi }}_{\mathbf {t}_{N}}^{y},\nu _{\mathbf {t}_{N}}^{y},\kappa _{\mathbf {t}_{N}}^{y}\right \}\) of hyperparameters. The quantities \(\nu _{\mathbf {t}_{N}}^{y}\) and \(\kappa _{\mathbf {t}_{N}}^{y}\) define our certainty about the prior knowledge (here, the set of SDEs presenting the dynamics of the model). If we take the conjugate priors for mean and covariance when the sampling is Gaussian, i.e., a normal-inverse-Wishart distribution (which depends on t N ), then
with \(\boldsymbol {\mu }_{\mathbf {t}_{N}}^{y}\) and \(\boldsymbol {\Sigma }_{\mathbf {t}_{N}}^{y}\) defined in (6) and (7). Therefore, the above assumption (ii) on the nature of the prior information means that
with \(\mathbf {m}_{\mathbf {t}_{N}}^{y}\) defined by (16) and (20) and \({\boldsymbol {\Psi }}_{\mathbf {t}_{N}}^{y}\) defined by (17) and (21). To see (26), note that from (25) and independence of \(\boldsymbol {\mu }_{\mathbf {t}_{N}}^{y}\) and \( \boldsymbol {\Sigma }_{\mathbf {t}_{N}}^{y}\), we have \(E_{\pi }\left [\!\boldsymbol {\mu }_{\mathbf {t}_{N}}^{y}\right ]=\breve {\mathbf {m}}_{\mathbf {t}_{N}}^{y}\) and \( E_{\pi }\left [\!\boldsymbol {\Sigma }_{\mathbf {t}_{N}}^{y}\right ]=\frac {\breve {{\boldsymbol {\Psi }}}_{\mathbf {t}_{N}}^{y}}{\kappa _{\mathbf {t}_{N}}^{y}-Np-1} \) (the latter is the mean of an inverse-Wishart distribution). The more confident we are about an a priori set of SDEs that is supposed to represent the underlying stochastic processes at t N y, the larger we might choose the values of \(\nu _{\mathbf {t}_{N}}^{y}\) and \(\kappa _{\mathbf {t}_{N}}^{y}\) and the more concentrated become the priors of the mean and covariance about \(\mathbf {m}_{\mathbf {t}_{N}}^{y}\) and \({\boldsymbol {\Psi }}_{\mathbf {t}_{N}}^{y}\), respectively. To ensure a proper prior distribution, we assume \(\breve {\boldsymbol {\Psi }}_{\mathbf {t}_{N}}^{y}\) is positive definite, \(\kappa _{\mathbf {t}_{N}}^{y}>Np-1\), and \(\nu _{\mathbf {t}_{N}}^{y}>0\) for all t N (cf. p. 126 in [16], p. 178 in [17], and p. 427 in [3]).
Given the preceding framework for uncertainty in the BCGP model, the optimal Bayesian classification theory can be directly adapted. Specifically, the normal-inverse-Wishart distribution prior as defined in (25) and the independence of \(\mathbf {X}_{\mathbf {t}_{N}}^{y}(\omega _{s})\) from training sample paths resemble the same set of conditions as in [6], i.e., having a normal-inverse-Wishart distribution prior and independence of future data points from training data points. As a result, we can follow the same set of machinery to find the effective class-conditional distributions of the processes (similar to equation (64) in [6]) and from there obtain the optimal discriminant. Therefore, extending the dimensionality of the problem to Np and using the set of parameters \(\left \{\breve {\mathbf {m}}_{\mathbf {t}_{N}}^{y},\breve {\boldsymbol {\Psi }}_{\mathbf {t}_{N}}^{y},\nu _{\mathbf {t}_{N}}^{y},\kappa _{ \mathbf {t}_{N}}^{y}\right \}\) in the discriminant presented by Eq. (65) in [6] yields
where
with
where \(\breve {\mathbf {m}}_{\mathbf {t}_{N}}^{y}\) and \(\breve {{\boldsymbol { \Psi }}}_{\mathbf {t}_{N}}^{y}\) are determined from (26), and \(\hat { \mathbf {\Sigma }}_{\mathbf {t}_{N}}^{y}\) and \(\hat {\boldsymbol {\mu }}_{\mathbf {t}_{N}}^{y}\) are the sample mean and sample covariance matrix obtained by using the sample path training sets \(\mathbf {S}_{\mathbf {t}_{N}}^{0}\) and \(\mathbf {S}_{\mathbf {t}_{N}}^{1}\) as follows:
As opposed to Section 4.1, where the discriminant can be applied to any future sample path with an arbitrary observation time vector, here, the discriminant depends on both the future and training observation time vectors. Thus, if the future observation time vector t L y contains only a set of time points t i where t i ∈t N y, one may easily apply the optimal discriminant. This is easily doable by reducing the dimensionality of the problem by considering the training sample paths only at t L y, i.e., by discarding the training sample points at those t N y not in t L y(denoted by t N y∖t L y). However, solving the case where t L y includes time points not included in t N y is more difficult and requires further study. In this case, although one is able to construct the class of prior knowledge for t L y (i.e., constructing \({\boldsymbol {\mu }} _{\mathbf {t}_{N}}^{y}\) and \(\boldsymbol {\Psi }_{\mathbf {t}_{N}}^{y}\)), the paucity of training sample paths at t L y∖t N y does not permit employing (27).
5 Performance analysis
In this section, we analyze the effect of prior knowledge in the form of stochastic differential equations on the performance of the stochastic discriminant, \(\psi _{\mathbf {t}_{N}}^{OBC}\left (\mathbf {x}_{\mathbf {t} _{N}}^{y}(\omega _{s})\right)\), defined by (27)–(29). As the metric of performance, we take the true error averaged over the sampling space. The true error of a discriminant trained on an observation time vector t N , i.e., \(\psi _{\mathbf {t}_{N}\phantom {\dot {i}\!}}(.)\), is the probability of misclassification, which by considering (11) is defined as
where X y denotes the class-conditional process that generates the future sample path \(\mathbf {X}_{\mathbf {t}_{N}}^{y}(\omega _{s})\) (we assume independence of future sample paths from training sample paths), \(\mathbf {S}_{\mathbf {t}_{N}}^{y}\) denotes the set of training sample paths from class y, and \(\alpha _{\mathbf {t}_{N}}^{y}\) is the mixing probability of the class-conditional process.
Recall that in this work, we consider a separate sampling scheme. With separate sampling in a classical binary classification problem where sample points are generated from two class-conditional densities, there is no sensible estimate of prior probabilities of classes from the sample [15]. In that case, either the ratio of the number of sample points in either class to the total sample size needs to reflect the corresponding prior probability of the class or the prior probabilities need to be known a priori; otherwise, classification rules or error estimation rules suffer performance degradation [15, 18, 19]. The same argument applies to this work in which we consider a binary classification of sample paths that are generated from two class-conditional processes under a separate sampling scheme. In this regard, we assume that the prior probability \(\alpha _{\mathbf {t}_{N}}^{y}\) is known a priori.
Taking expectation over the sample space, that is over the mixture of Gaussian processes with the means and covariance matrices defined by (16), (20), (17), and (21), yields
As benchmarks for evaluating the performance of \(\psi _{\mathbf {t}_{N}}^{\text {OBC}} \left (\mathbf {x}_{\mathbf {t}_{N}}^{y}(\omega _{s})\right)\), we compare its performance to (1) the performance of the stochastic QDA, \(\psi _{\mathbf {t}_{N}}^{\text {QDA}}\left (\mathbf {X}_{\mathbf {t}_{N}}^{y}(\omega _{s})\right)\), which is defined by (23) and (24), where l y =n y , with n y indicating the number of available sample paths, and (2) the performance of a Bayes classifier obtained by plugging (16), (17), (20), and (21), into (24).
5.1 Synthetic experiments
5.1.1 Experimental set-up
The following steps are used to set up the experiments:
-
1.
To fix the ground-truth model governing the underlying dynamics of the data, we consider a set of three-dimensional SDEs (p=3) defined by (15) along with the following set of parameters:
$$ {\small{\begin{aligned} \mathbf{A}^{0}(t)&=\mathbf{A}^{1}(t)=[\!0.01,0.01,0.01]^{T},\\ \mathbf{a}^{0}(t)&=\mathbf{a}^{1}(t)=[\!0,0,0]^{T}, \\ &\mathbf{X}_{t_{0}}^{0}(\omega)=[\!0,0,0]^{T},\quad \mathbf{X}_{t_{0}}^{1}(\omega)=[\!0.25,0.25,0.25]^{T}, \\ &\mathbf{B}^{0}(t)=\mathbf{B}^{1}(t)=0.1\!\times \left\{ \begin{array}{ll} \sigma^{2}=1 &\text{diagonal elements} \\ \rho =0.4 & \text{otherwise} \end{array}\right.. \end{aligned}}} $$((33))The only difference between the SDEs describing X 0 and X 1 is in the constant initial conditions. Figure 1 presents a single sample path of these two three-dimensional processes for 0≤t≤100.
Fig. 1 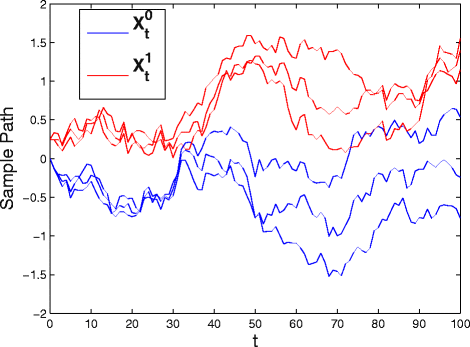
A single sample path taken from the two three-dimensional processes described by the set of parameters introduced in (33)
-
2.
Use the ground-truth set of SDEs to generate a set of training sample paths, \(\mathbf {S}_{\mathbf {t}_{N}}^{y}\), of size n y for class y=0,1. We let n 0=n 1=n, where n∈, let the length of the observation time vector be N=20, and take [ t 1,t 2,...,t N ] such that t i −t i−1=1, i=2,…,20.
-
3.
Use the ground-truth set of SDEs to generate a set of test sample paths, \(\mathbf {S}_{\mathbf {t}_{N}}^{y,\,\text {test}}\), of size n y, test=2,000 for class y=0,1, where n 0, test=n 1, test=n test.
-
4.
Use \(\mathbf {S}_{\mathbf {t}_{N}}^{0}\cup \mathbf {S}_{\mathbf {t} _{N}}^{1}\) to train the stochastic QDA, \(\psi _{\mathbf {t}_{N}}^{\text {QDA}}\left (\mathbf {x}_{\mathbf {t}_{N}}^{y}(\omega _{s})\right)\), which is defined by (23) and (24) with l y=n y. Apply the trained classifier to the set of test sample paths, \(\mathbf {S}_{\mathbf {t} _{N}}^{0,\,\text {test}}\cup \mathbf {S}_{\mathbf {t}_{N}}^{1,\,\text {test}}\), to determine the true error, \(\epsilon _{\mathbf {t}_{N}}^{\text {QDA}}\), which is defined by replacing \(\psi _{\mathbf {t}_{N}}\left (\mathbf {X}_{\mathbf {t}_{N}}^{y}(\omega _{s})\right)\) with \(\psi _{\mathbf {t}_{N}}^{\text {QDA}}\left (\mathbf {X}_{\mathbf {t}_{N}}^{y}(\omega _{s})\right)\) in (31). This procedure obtains an accurate estimate of true error.
-
5.
Assume a set of SDEs obtained from prior knowledge (a priori SDEs). Let this a priori set of SDEs be presented by replacing A y(t), B y(t), A y(t), and \(\mathbf {X} _{t_{0}}^{y}(\omega)\) in (15) with \(\tilde {\mathbf {A}}^{y}(t)\), \(\tilde {\mathbf {B}}^{y}(t)\), \(\tilde {\mathbf {A}}^{y}(t)\), and \(\tilde {\mathbf { X}}_{t_{0}}^{y}(\omega)\), respectively. To examine the effects of deviations in the drift vector and dispersion matrix in the a priori set of SDEs from the ground-truth model introduced in (33), we assume
-
\(\tilde {\mathbf {A}}^{0}(t)={\mathbf {A}}^{0}(t)\), \(\tilde {\mathbf {B}} ^{0}(t)={\mathbf {B}}^{0}(t)\), \(\tilde {\mathbf {X}}^{0}_{t_{0}}(\omega)= \mathbf {X}_{t_{0}}^{0}(\omega)\), \(\tilde {\mathbf {X}}^{1}_{t_{0}}(\omega)= \mathbf {X}_{t_{0}}^{1}(\omega)\), \(\tilde {\mathbf {a}}^{0}(t)=\mathbf {a} ^{0}(t),\tilde {\mathbf {a}}^{1}(t)=\mathbf {a}^{1}(t)\).
-
To study the effect of shift in the drift vector, we take \(\tilde { \mathbf {A}}^{1}(t)={\mathbf {A}}^{1}(t)+[\!\Delta \mu,\Delta \mu,\Delta \mu ]^{T}\), where Δ μ=0,0.1,0.2,0.3. Here we assume \(\tilde {\mathbf {B}} ^{1}(t)={\mathbf {B}}^{1}(t)\).
-
To study the effect of shift in the dispersion matrix, we assume the off-diagonal elements of \(\tilde {\mathbf {B}}^{1}(t)\) are defined by replacing ρ with ρ d in (33), where ρ d −ρ=Δ ρ=0,0.03,0.06,0.1. Here we assume \(\tilde {\mathbf {A}} ^{1}(t)={\mathbf {A}}^{1}(t)\).
-
The hyperparameters defining our uncertainty about the specific choice of a priori SDEs (in fact, about the resultant prior distributions) are \(\nu _{\mathbf {t}_{N}}^{0}=\nu _{\mathbf {t}_{N}}^{1}=\kappa _{\mathbf {t} _{N}}^{0}=\kappa _{\mathbf {t}_{N}}^{1}=Np+\kappa \). The choice of N p+κ, κ=20,50,100,500, is made to have proper prior distributions (see Section 4.2).
-
-
6.
Generate 2,000 sample paths from the a priori set of SDEs introduced in Step 5. These sample paths are used to calculate the hyperparameters \(\mathbf {m}_{\mathbf {t}_{N}}^{y}\) and \({\boldsymbol {\Psi }}_{ \mathbf {t}_{N}}^{y}\) being used in (26) (alternatively, one may solve (16), (17), (20), and (21) directly and use them in (26)).
-
7.
Use \(\mathbf {m}_{\mathbf {t}_{N}}^{y}\) and \({\boldsymbol {\Psi }}_{ \mathbf {t}_{N}}^{y}\) obtained from Step 6 along with \(\mathbf {S}_{\mathbf {t} _{N}}^{0}\cup \mathbf {S}_{\mathbf {t}_{N}}^{1}\) to train \(\psi _{\mathbf {t} _{N}}^{\text {OBC}}\left (\mathbf {x}_{\mathbf {t}_{N}}^{y}(\omega _{s})\right)\), which is defined in (27). Apply the trained classifier to the set of test sample paths, \(\mathbf {S}_{\mathbf {t}_{N}}^{0,\,\text {test}}\cup \mathbf {S}_{ \mathbf {t}_{N}}^{1,\,\text {test}}\), to determine the true error, \(\epsilon _{ \mathbf {t}_{N}}^{\text {OBC}}\), which is defined by replacing \(\psi _{\mathbf {t}_{N}} \left (\mathbf {X}_{\mathbf {t}_{N}}^{y}(\omega _{s})\right)\) with \(\psi _{\mathbf {t}_{N}}^{\text {OBC}}\left (\mathbf {x}_{\mathbf {t}_{N}}^{y}(\omega _{s})\right)\) in (31).
-
8.
Repeat Steps 2 through 7 a total of T=1,000 times to estimate \( E\left [\epsilon _{\mathbf {t}_{N}}^{\text {QDA}}\right ]\) and \(E\left [\epsilon _{\mathbf {t}_{N}}^{\text {OBC}}\right ] \).
-
9.
Generate 2,000 sample paths from the ground-truth set of SDEs introduced in (33). Use these sample paths to train the stochastic QDA, \(\psi _{\mathbf {t}_{N}}^{\text {QDA}}\left (\mathbf {x}_{\mathbf {t} _{N}}^{y}(\omega _{s})\right)\), which is defined by (23) and (24) with l y=2,000. This provides an accurate estimate of the Bayes (optimal) classifier. Apply this classifier to \(\mathbf {S}_{\mathbf {t} _{N}}^{0,\,\text {test}}\cup \mathbf {S}_{\mathbf {t}_{N}}^{1,\,\text {test}}\) to obtain the Bayes error, which is a lower bound on the error of any classifier. Note that in our experiments obtaining the Bayes error is possible since we have complete knowledge of the underlying ground-truth models.

5.1.2 Results
Figure 2 shows the effect of a shift in the drift vector from the ground-truth model via plots of the expected true error of \(\psi _{\mathbf {t}_{N}}^{\text {QDA}}(.)\) and \(\psi _{\mathbf {t}_{N}}^{\text {OBC}}(.)\) as functions of the size of training sample paths and κ for y=0,1, \(\tilde {\mathbf {B}}^{y}(t)={\mathbf {B}}^{y}(t)\), \(\tilde {\mathbf {X}} ^{y}_{t_{0}}(\omega)=\mathbf {X}_{t_{0}}^{y}(\omega)\), \(\tilde {\mathbf {A}} ^{0}(t)={\mathbf {A}}^{0}(t)\), and \(\tilde {\mathbf {A}}^{1}(t)={\mathbf {A}} ^{1}(t)+[\!\Delta \mu,\Delta \mu,\Delta \mu ]^{T}\), where Δ μ=0,0.1,0.2,0.3. If the set of a priori SDEs is equivalent or close to the ground-truth model, e.g., Δ μ=0 or Δ μ=0.1, then \(\psi _{\mathbf {t}_{N}}^{\text {OBC}}(.)\) outperforms \(\psi _{\mathbf {t}_{N}}^{\text {QDA}}(.)\) for a wide range of training sample sizes and κ. The more the prior distribution generated from the set of a priori SDEs is concentrated about the true underlying parameters of the model and the larger κ, the better is the performance achieved by using \(\psi _{\mathbf {t}_{N}}^{\text {OBC}}(.)\).

Expected true error, \(E\left [\protect \epsilon ^{\text {QDA}}_{\mathbf {t}_{N}}\right ]\) and \(E\left [\protect \epsilon ^{\text {OBC}}_{\mathbf {t}_{N}}\right ]\), as a function of number of training sample paths in each class and various choices of Δ μ and κ. The dashed line shows the Bayes error
Figure 3 presents the effect of the discrepancy between the dispersion matrix of the ground-truth model and that of the a priori set of SDEs. Again, the closer the prior knowledge is to the ground-truth model and the larger κ, the better is the performance achieved by using \(\psi _{\mathbf {t}_{N}}^{\text {OBC}}(.)\).

Expected true error, \(E\left [\epsilon ^{\text {QDA}}_{\mathbf {t}_{N}}\right ]\) and \(E\left [\epsilon ^{\text {OBC}}_{\mathbf {t}_{N}}\right ]\), as a function of number of training sample paths in each class and various choices of Δ ρ and κ. The dashed line shows the Bayes error
5.2 An experiment inspired by a model of the evolutionary process
In this section, we use a form of an Ornstein-Uhlenbeck process introduced in [20] for modeling the evolutionary change of species. This model has been recently employed by [21] to simulate quantitative trait data as a function of single nucleotide polymorphism (SNP) states. The model is presented by the following SDE:
where \({X}_{t}^{y}\) is the quantitative trait value in a species y, θ y is the primary target value of the trait, \({X_{a}^{y}}\) is the mean state in an ancestor a, and \({W}_{t}^{y}\) represents Brownian motion. The parameter β y is the rate of adaptation of species y to the target value—a low rate of adaptation means very slow evolution while a large β y practically indicates an instantaneous adaptation. The parameter σ y is an indicator of perturbation due to random selective factors such as random mutations and environmental fluctuations [20]. Similar to [21], we assume the value of the primary target is constant over the history of the species. Nevertheless, the model in (34) can be extended to include situations where the primary target can change over the evolutionary history of the species (see [20]).
Using the model of (34), we generate the evolutionary histories of a quantitative trait of two species, 0 and 1, over a time span of 30 million years with time steps of 1 million years. Similarly to [20, 21], to fix the ground-truth model that generates the data, we vary values of β y, take σ y=1, and assume θ 0=80 and θ 1=85. Furthermore, we assume both species have a common ancestor at the state \({X_{a}^{y}}=1\). Figure 4 presents 20 sample paths from each of these evolutionary processes for the case where β 0=β 1=β, β=0.1 (Fig. 4 a) and β=0.15 (Fig. 4 b). A larger β indicates a faster adaptation of species to the target value. The problem considered here is to use a set of a priori SDEs in constructing a classifier to differentiate the evolutionary history of an n-size population of species 0 from an n-size population of species 1, where n∈[ 60,140].

Multiple sample paths taken from the two one-dimensional evolutionary processes for two values of adaptation rate, (a): β=0.1; (b): β=0.15
The general protocol for evaluating the performance of ψ t N OBC(.) is similar to Section 5.1, except for replacing the ground-truth model (33) with (34) and using the following the step instead of Step 5:
-
Assume a set of SDEs obtained from prior knowledge (a priori SDEs). Let this a priori set of SDEs be presented by replacing β y, θ y, \({X_{a}^{y}}\), and σ y by \(\tilde {\beta } ^{y}\), \(\tilde {\theta }^{y}\), \(\tilde {X}_{a}^{y}\), and \(\tilde {\sigma }^{y}\), respectively, in (34). To examine the effect of deviation of the adaptation rate in the a priori set of SDEs from the ground-truth model, we let \( \tilde {\theta }^{y}={\theta }^{y}\), \(\tilde {\sigma }^{y}={\sigma }^{y}\), \( \tilde {X}_{a}^{y}={X}^{y}\), and \(\tilde {\beta }^{0}={\beta }^{0}\) and take \( \tilde {\beta }^{1}={\beta }^{1}+\Delta \beta \).
5.2.1 Results
Figures 5 and 6 (β=0.1 and β=0.15, respectively) show the effect of a deviation from the true rate of adaptation to the target value by considering \(\tilde {\beta }^{1}={\beta } ^{1}+\Delta \beta,\) where Δ β=0, 0.02, 0.04, 0.06. They provide plots of the expected true error of \(\psi _{\mathbf {t}_{N}}^{\text {QDA}} (.)\) and \(\psi _{\mathbf {t}_{N}}^{\text {OBC}}(.)\) as functions of the size of training sample paths and κ. In both figures, the closer the prior knowledge is to the ground-truth evolutionary models, the better is the performance achieved by using \(\psi _{\mathbf {t}_{N}}^{\text {OBC}}(.)\). The performance deteriorates and eventually becomes worse than \(\psi _{ \mathbf {t}_{N}}^{\text {QDA}}(.)\) as the prior knowledge diverges from the ground-truth model and the certainty about the prior knowledge increases (a bad combination when utilizing prior knowledge). In addition, comparing Figs. 5 and 6 shows that the smaller is the true value of β and the more destructive is a fixed deviation of prior knowledge from the true β.

Expected true error, \(E\big [\protect \epsilon ^{\text {QDA}}_{\mathbf {t}_{N}}\big ]\) and \(E\left [\protect \epsilon ^{\text {OBC}}_{\mathbf {t}_{N}}\right ]\), as a function of number of training sample paths in each class and various choices of Δ β and κ and for β=0.1. The dashed line shows the Bayes error

Expected true error, \(E\big [\protect \epsilon _{\mathbf {t}_{N}}^{\text {QDA}}\big ]\) and \(E\left [\protect \epsilon _{\mathbf {t}_{N}}^{\text {OBC}}\right ]\), as a function of number of training sample paths in each class and various choices of Δ β and κ and for β =0.15. The dashed line shows the Bayes error
6 Conclusions
This paper provides the first instance in which prior knowledge in the form of SDEs is used to construct a prior distribution over an uncertainty class of feature-label distributions for the purpose of optimal classification. Given the ubiquity of small samples in biomedicine and other areas where sample data is expensive, time-consuming, limited by regulation, or simply unavailable, we have previously made the point that prior knowledge is the only avenue available. To achieve the mapping of SDE prior knowledge into a prior distribution, we have taken advantage of the form and Gaussianity of (12). This mapping is heavily dependent on the form of the SDEs, and one can expect widely varying mappings for different SDE settings.
In general, all parameters used in the a priori set of SDEs can affect the performance of \(\psi _{\mathbf {t}_{N}}^{\text {OBC}}(.)\). These parameters include every element of the matrices \(\tilde {\mathbf {A}}^{y}(t)\) and \(\tilde {\mathbf {B}}^{y}(t)\) and all the elements of the vectors \(\tilde { \mathbf {a}}^{y}(t)\) and \(\tilde {\mathbf {X}^{y}}_{t_{0}}(\omega)\) used in the SDE’s presentation in (15). For example, in the experiment of the evolutionary change of species considered in (34), a deviation from each of the parameters, namely \(\tilde {\beta }^{y}\), \(\tilde {\sigma } ^{y} \), \(\tilde {\theta }^{y}\), and \(\tilde {X}_{a}^{y},\) can affect the performance of \(\psi _{\mathbf {t}_{N}}^{\text {OBC}}(.)\). Although simulation studies can elucidate the effects of deviation of prior knowledge from the ground-truth model (as done herein), it would be beneficial to analytically characterize the performance of \(\psi _{\mathbf {t}_{N}}^{\text {OBC}} (.)\) in terms of all the hyperparameters; however, this may be very difficult to accomplish. One possible approach may be to use an asymptotic Bayesian framework [22] to characterize the performance of \(\psi _{\mathbf {t}_{N}}^{\text {OBC}}(.)\) in terms of sample size, dimensionality, and hyperparameters.
Recognizing that the construction of robust classifiers is simply a special case of optimal Bayesian classification where there are no sample data, so that the “posterior” is identical to the prior [7], the application of SDEs in this paper is at once applicable to optimal robust classification in a stochastic setting. Beyond that, one can consider the more general setting of optimal Bayesian robust filtering of random processes, where optimization across an uncertainty class of random processes, ideal and observed, is relative to process characteristics such as the auto- and cross-correlation functions [23]. Whereas in this paper we have considered using SDE prior knowledge to construct prior distributions governing uncertainty classes of feature-label distributions, it seems feasible to use SDE knowledge to construct prior distributions governing uncertainty classes of random-process characteristics in the case of optimal filtering. Of course, one must confront the increased abstraction presented by canonical representation of random processes [24, 25]; nevertheless, so long as one remains in the framework of second-order canonical expansions, it should be doable.
7 Appendix
7.1 Definition of q-dimensional Wiener process
A one-dimensional Wiener process over [ 0,T] is a Gaussian process W={W t :t≥0} satisfying the following properties:
-
For 0≤t 1<t 2<T, \(W_{t_{2}}-W_{t_{1}}\) is distributed as \( \sqrt {t_{2}-t_{1}}N\left (0,\sigma ^{2}\right)\), where σ>0 (for the standard Wiener process, σ=1).
-
For 0≤t 1<t 2<t 3<t 4<T, \(W_{t_{4}}-W_{t_{3}}\) is independent of \(W_{t_{2}}-W_{t_{1}}\).
-
W 0=0 with probability 1.
-
The sample paths of W are almost surely continuous everywhere.
In general, a q-dimensional Wiener process is defined using the homogenous Markov process X t for t∈[t 0,T]. Let \(P(t_{1},x;t_{2}, B)=P(\mathbf {X}_{t_{2}\phantom {\dot {i}\!}} \in B|\mathbf {X}_{t_{1}\phantom {\dot {i}\!}}=x)\) denote the transition probabilities of a Markov process X t for t 1<t 2. For fixed values of t 1, x, and t 2, P(t 1,x;t 2,.) is a probability function (measure) on the σ-algebra \(\mathcal {B}\) of Borel subsets of the sample space R q. Intuitively, P(t 1,x;t 2,B) is the probability that the process be in the set \(B\in \mathcal {B}\) at time t 2 given it was in state x at time t 1. A Markov process is homogenous with respect to t if its transition probability P(t 1,x;t 2,B) is stationary. That is, for t 0<t 1<t 2<T and t 0<t 1+u<t 2+u<T, it satisfies
In this case P(t 1,x;t 2,B) is commonly denoted by P(t 2−t 1,x;B). A q-dimensional Wiener process is a q-dimensional homogenous Markov process defined on [0,∞) with stationary transition probability defined by a multivariate Gaussian distribution as follows:
Therefore, each dimension of a q-dimensional Wiener process is a one-dimensional Wiener process per se.
7.2 Computational complexity
The computational complexity of the algorithm is determined by the computational cost of solving the set of SDEs from the Euler-Maruyama scheme (see Section 4.1) along with the computational cost of evaluating (27). The computational cost of the Euler-Maruyama scheme per sample path is inversely proportional to Δ t [26], where Δ t=T/N, with T and N being defined in Section 3. Thus, for l=l 0+l 1 sample paths, it is O(l/Δ t). In (27), the computational cost of evaluating \(\mathbf {x}_{\mathbf {t}_{N}}^{y}(\omega _{s})-{\mathbf {m}}_{\mathbf {t}_{N}}^{0\;\ast },\) with y=0,1, breaks down to a computation of \(\breve {\mathbf {m}}_{\mathbf {t}_{N}}^{y}\) and \(\hat {\boldsymbol {\mu }}_{\mathbf {t}_{N}}^{y}\), which are operations with computational costs of O(l y N p) and O(n y N p), respectively.
Computation of \({{\boldsymbol {\Pi }}_{\mathbf {t}_{N}}^{y\;-1}}\) in (27) by Gaussian elimination is an O(max{n y,N p}N 2 p 2)+O(l y N 2 p 2) operation (cf. section 3.7.2 in [27]). This will be further simplified because, in order to have a positive definite \(\breve {{ \boldsymbol {\Psi }}}_{\mathbf {t}_{N}}^{y}\), we assume we generate many sample paths by solving the set of SDEs such that l y>>N p (see Section 4.1), but since \({\boldsymbol {\Psi }}_{\mathbf {t}_{N}}^{y\;\ast }\) and \({{ \boldsymbol {\Pi }}_{\mathbf {t}_{N}}^{y\;-1}}\) defined in (29) become positive definite, we do not need to impose the condition of n y>N p. Having a realistic assumption on the number of available sample paths, we can assume l y>>n y, and therefore, the computation of \({{\boldsymbol {\Pi } }_{\mathbf {t}_{N}}^{y\;-1}}\) becomes an O(l y N 2 p 2) calculation. Furthermore, the product of \(\mathbf {x}_{\mathbf {t}_{N}}^{y}(\omega _{s})-{ \mathbf {m}}_{\mathbf {t}_{N}}^{0\;\ast }\) with \({{\boldsymbol {\Pi }}_{\mathbf { t}_{N}}^{y\;-1}}\) is an O(N 2 p 2) calculation. Altogether, by assuming 1/Δ t<(N p)2 and k 0+k 1+N p<(N p)2, the overall computational cost of \(\psi _{\mathbf {t}_{N}}^{\text {OBC}}\left (\mathbf {x}_{\mathbf {t}_{N}}^{y}(\omega _{s})\right)\) is O(max{l 0,l 1}N 2 p 2).
Using a similar approach, we see that the computational cost of QDA, which is solely constructed by using n 0+n 1 training sample paths from classes 0 and 1 (i.e., no prior knowledge) is O(max{n 0,n 1}N 2 p 2). We also note that for computing QDA we need to have min{n 0,n 1}>N p because, otherwise, the sample covariance matrices used in QDA are not invertible.
References
Braga-Neto, UM, & Dougherty, ER. (2015). Error Estimation for Pattern Recognition. New York: Wiley-IEEE Press.
Kay, S. (1993). Fundamentals of Statistical Signal Processing: Estimation Theory. New Jersey: Prentice-Hall.
Carlin, BP, & Louis, TA. (2008). Bayesian Methods for Data Analysis. Boca Raton: CRC Press.
Dalton, L, & Dougherty, ER (2011). Bayesian minimum mean-square error estimation for classification error–part I: definition and the Bayesian MMSE error estimator for discrete classification. IEEE Transactions on Signal Processing, 59(1), 115–129.
Dalton, L, & Dougherty, ER (2011). Bayesian minimum mean-square error estimation for classification error–part II: linear classification of Gaussian models. IEEE Transactions on Signal Processing, 59(1), 130–144.
Dalton, L, & Dougherty, ER (2013). Optimal classifiers with minimum expected error within a Bayesian framework – part I: discrete and Gaussian models. Pattern Recognition, 46, 1301–1314.
Dalton, L, & Dougherty, ER (2013). Optimal classifiers with minimum expected error within a Bayesian framework – part II: properties and performance analysis. Pattern Recognition, 46, 1288–1300.
Knight, J, Ivanov, I, Dougherty, ER (2014). MCMC implementation of the optimal Bayesian classifier for non-gaussian models: model-based RNA-seq classification. BMC Bioinformatics, 15. doi:10.1186/s12859-014-0401-3.
Esfahani, MS, & Dougherty, ER (2014). Incorporation of biological pathway knowledge in the construction of priors for optimal Bayesian classification. IEEE/ACM Transactions on Computational Biology and Bioinformatics, 11, 202–218.
Esfahani, MS, & Dougherty, ER (2015). An optimization-based framework for the transformation of incomplete biological knowledge into a probabilistic structure and its application to the utilization of gene/protein signaling pathways in discrete phenotype classification. IEEE/ACM Transactions on Computational Biology and Bioinformatics. doi:10.1109/TCBB.2015.2424407.
Jaynes, ET (1968). Prior probabilities. IEEE Transactions on Systems Science and Cybernetics, 4, 227–241.
Kloeden, PE, & Platen, E. (1995). Numerical Solution of Stochastic Differential Equations. New York: Springer.
Arnold, L. (1974). Stochastic Differential Equations: Theory and Applications. New York: Wiley.
Higham, D (2001). An algorithmic introduction to numerical simulation of stochastic differential equations. SIAM Review, 43, 525–546.
Anderson, TW (1951). Classification by multivariate analysis. Psychometrika, 16, 31–50.
Murphy, KP. (2012). Machine Learning: A Probabilistic Perspective. Cambridge: MIT Press.
DeGroot, MH. (1970). Optimal Statistical Decisions. New York: McGrawHill.
Esfahani, MS, & Dougherty, ER (2014). Effect of separate sampling on classification accuracy. Bioinformatics, 30, 242–250.
Braga-Neto, UM, Zollanvari, A, Dougherty, ER (2014). Cross-validation under separate sampling: strong bias and how to correct it. Bioinformatics, 30, 3349–3355.
Hansen, TF (1997). Stabilizing selection and the comparative analysis of adaptation. Evolution, 51, 1341–1351.
Thompson, K, & Kubatko, LS (2013). Using ancestral information to detect and localize quantitative trait loci in genome-wide association studies. BMC Bioinformatics, 14. doi:10.1186/1471-2105-14-200.
Zollanvari, A, & Dougherty, ER (2014). Moments and root-mean-square error of the Bayesian MMSE estimator of classification error in the Gaussian model. Pattern Recognition, 47, 2178–2192.
Dalton, L, & Dougherty, ER (2014). Intrinsically optimal Bayesian robust filtering. IEEE Transactions on Signal Processing, 62(3), 657–670.
Pugachev, VS. (1965). Theory of Random Functions and Its Applications to Control Problems. Oxford: Pergamon.
Dougherty, ER. (1999). Random Processes for Image and Signal Processing. New York: SPIE Press and IEEE Presses.
Higham, DJ (2015). An introduction to multilevel Monte Carlo for option valuation. International Journal of Computer Mathematics, 92(12).
Duda, RO, Hart, PE, Stork, DG. (2000). Pattern Classification. New York: Wiley.
Author information
Authors and Affiliations
Corresponding author
Additional information
Competing interests
The authors declare that they have no competing interests.
Additional file
Additional file 1
Supplementary information. I. Definition of QDA in a classical setting. II. Error estimation accuracy. III. Bayesian MMSE error estimator. IV. Review of literature pertaining to classification of stochastic processes.
Rights and permissions
Open Access This article is distributed under the terms of the Creative Commons Attribution 4.0 International License(http://creativecommons.org/licenses/by/4.0/), which permits unrestricted use, distribution, and reproduction in any medium, provided you give appropriate credit to the original author(s) and the source, provide a link to the Creative Commons license, and indicate if changes were made.
About this article

Cite this article
Zollanvari, A., Dougherty, E.R. Incorporating prior knowledge induced from stochastic differential equations in the classification of stochastic observations. J Bioinform Sys Biology 2016, 2 (2016). https://doi.org/10.1186/s13637-016-0036-y
Received:
Accepted:
Published:
DOI: https://doi.org/10.1186/s13637-016-0036-y