- Research Article
- Open access
- Published:
Algorithms and Complexity Analyses for Control of Singleton Attractors in Boolean Networks
EURASIP Journal on Bioinformatics and Systems Biology volume 2008, Article number: 521407 (2008)
Abstract
A Boolean network (BN) is a mathematical model of genetic networks. We propose several algorithms for control of singleton attractors in BN. We theoretically estimate the average-case time complexities of the proposed algorithms, and confirm them by computer experiments. The results suggest the importance of gene ordering. Especially, setting internal nodes ahead yields shorter computational time than setting external nodes ahead in various types of algorithms. We also present a heuristic algorithm which does not look for the optimal solution but for the solution whose computational time is shorter than that of the exact algorithms.
1. Introduction
One of the important challenges of computational systems biology and bioinformatics is to develop a control theory for biological systems [12]. Development of such a control theory is interesting from both a theoretical viewpoint and a practical viewpoint. From a theoretical viewpoint, biological systems are highly nonlinear. For control of linear systems, extensive studies have been done, and rigorous theories and useful methods have been developed. Furthermore, many of these methods have been applied to control various kinds of real systems. However, it is recognized that control of nonlinear systems is far more difficult than control of linear systems. Though there are some established methods for control of nonlinear systems [34], these can only be applied to certain classes/special cases. In particular, it is very difficult to control large-scale nonlinear systems. From a practical viewpoint, as Kitano wrote [12], identification of a set of perturbations that induces desired changes in cellular behaviors may be useful for systems-based drug discovery and cancer treatment. For example, Takahashi (this author along with Morihiro Hayashida contributed equally to this work) and Yamanaka developed induced pluripotent stem cells (iPS cells) by introducing 4 kinds of transcription factors (Oct3/4, Sox2, c-Myc, Klf4) into fibroblast cells of mouse [5]. Furthermore, Takahashi et al. [6] and Yu et al. [7] independently succeeded to develop iPS cells by introducing 4 kinds of factors into human cells. It is to be noted that Yamanaka et al. introduced 4 transcription factors of Oct3/4, Sox2, c-Myc, and Klf4 into fibroblast cells, whereas Thomson et al. introduced 4 factors of OCT4, SOX2, NANOG, and LIN28 into somatic cells. Though these seminal discoveries were achieved based on their knowledge, experience, and many experiments, systematic methods might help such kind of works. Therefore, we study systematic methods for control of biological systems. In this paper, we focus on control of gene regulatory networks because these networks play a fundamental role in cells and may be efficiently controlled by overexpression and suppression of genes.
Various kinds of mathematical models have been proposed for modeling gene regulatory networks. These models include neural networks, differential equations, Petri nets, Boolean networks, probabilistic Boolean networks (PBNs), and multivariate Markov chain model [8–11]. Among these models, Boolean network (BN) [12–14] has been well studied. BN is a very simple model; each node (e.g., gene) takes either 0 (inactive) or 1 (active), and the states of nodes change synchronously. Although BN is very simple, its dynamic process is complex and can give insight into the global behavior of large genetic regulatory networks [15].
The total number of possible global states for a Boolean network with  genes is
genes is  . However, for any initial condition, the system will eventually evolve into a limited set of stable states called attractors. The set of states that can lead the system to a specific attractor is called the basin of attraction. Each attractor can contain one or many states. An attractor having only one state is called a singleton attractor. Otherwise, it is called a cyclic attractor. Attractors are biologically interpreted so that different attractors correspond to different cell types [14] or different cell states [16].
. However, for any initial condition, the system will eventually evolve into a limited set of stable states called attractors. The set of states that can lead the system to a specific attractor is called the basin of attraction. Each attractor can contain one or many states. An attractor having only one state is called a singleton attractor. Otherwise, it is called a cyclic attractor. Attractors are biologically interpreted so that different attractors correspond to different cell types [14] or different cell states [16].
Motivated by this biological interpretation, extensive studies have been done on the average-case analysis of the number and length of attractors in randomly generated BNs [1417–19], although there is no conclusive result. Recently, several methods have been developed for efficiently finding or enumerating attractors in BNs [20–23], whereas it is known that finding a singleton attractor (i.e., a fixed point) is NP-hard [2425]. Devloo et al. developed a method using transformation to a constraint satisfaction problem [20]. Garg et al. developed a method based on binary decision diagrams (BDDs) [21]. Irons developed a method that makes use of small subnetworks [22]. However, theoretical analysis of the average-case complexity was not addressed in these works. We recently developed algorithms for identifying singleton attractors and small attractors, and analyzed the average-case time complexities of these algorithms [23].
Finding a sequence of control actions for BNs is another important topic on BNs. Datta et al. proposed methods for finding control actions for probabilistic Boolean networks (PBNs) [26–28], where a PBN is a probabilistic extension of a BN [29]. In their approach, the control problem is defined as minimization of the total of control cost and the cost of terminal state. The control cost is defined as the cost of applying control inputs in some particular states, and higher terminal costs are usually assigned to those undesirable states. Their approach is based on the theory of controlled Markov chains, and makes use of the theory of probabilistic dynamic programming. They extended their approach for handling context-sensitive PBNs [30] and/or infinite-horizon optimal control [31]. Since BNs are special cases of PBNs, their methods can also be applied to finding control actions for BNs. However, all of these approaches need to handle  matrices, which limits application of these approaches only to small size (e.g., less than 20 nodes) networks. Therefore, we studied computational complexity of the control problem on BN and PBN, and proved that finding an optimal control strategy is NP-hard for both BN and PBN [32]. In order to break the barrier of computational complexity, an approximate finite-horizon optimal control has been introduced [33] and a heuristic method based on
matrices, which limits application of these approaches only to small size (e.g., less than 20 nodes) networks. Therefore, we studied computational complexity of the control problem on BN and PBN, and proved that finding an optimal control strategy is NP-hard for both BN and PBN [32]. In order to break the barrier of computational complexity, an approximate finite-horizon optimal control has been introduced [33] and a heuristic method based on  -learning algorithm for approximating the optimal infinite-horizon control policy has been proposed [34]. However, application of these approaches is still limited to small networks.
-learning algorithm for approximating the optimal infinite-horizon control policy has been proposed [34]. However, application of these approaches is still limited to small networks.
In this paper, we propose a new model for control of BN, that is, control of attractors of BN. Though our model can be extended to cyclic attractors to some extent (as shown in Section 3.9), here we focus on singleton attractors. Since cyclic attractors correspond to cell cycles appearing in such cases as cell division and cell growth whereas singleton attractors correspond to steady states of cells or cell types, it is reasonable to begin with singleton attractors. We assume that a BN and a score function are given as an input, where the score function indicates the closeness of the attractor state to the desired state. We also assume that nodes in a BN are divided into internal nodes and external nodes, where states of external nodes can only be controlled. Then, our objective is to determine 0/1 states of external nodes so that the score of the resulting singleton attractor is maximized. However, if there exist multiple attractors, the attractor into which a BN is evolved depends on an initial state of a BN. Since it is very difficult to know the initial state exactly, we modify the objective so that the minimum score of the singleton attractors is maximized or exceeds a given threshold. In this model, external nodes correspond to candidate genes and/or transcription factors to be added or to be deleted (suppressed), and the objective is to make a cell to go to a preferable state regardless of the current state of the cell.
In order to solve the proposed problem, we develop several algorithms based on our previous work [23]. In [23], we developed a series of algorithms for finding singleton and small attractors in a BN. The most important feature of the algorithms is that the average-case time complexity was theoretically analyzed and was experimentally corroborated. It was shown that most of these are much faster than  if the maximum indegree is bounded by some constant
if the maximum indegree is bounded by some constant  . For example, one of the algorithms works in
. For example, one of the algorithms works in  time and
time and  time (in the average case) for
time (in the average case) for  and
and  respectively, which are much faster than
respectively, which are much faster than  . Many of the algorithms proposed in this paper have similar properties. For example, it is shown that one of the algorithms works in
. Many of the algorithms proposed in this paper have similar properties. For example, it is shown that one of the algorithms works in  and
and  times for
times for  and
and  respectively, under some reasonable conditions. Though these time complexities are worse than those in [23], the problem considered in this paper is much more difficult than the one in [23]. Therefore, these results are reasonable and are still much faster than
respectively, under some reasonable conditions. Though these time complexities are worse than those in [23], the problem considered in this paper is much more difficult than the one in [23]. Therefore, these results are reasonable and are still much faster than  . It is to be noted that some of the proposed algorithms are far from straightforward extensions of [23], and novel ideas are introduced in some of the theoretical analyses. Most of the theoretical results are corroborated through computational experiments.
. It is to be noted that some of the proposed algorithms are far from straightforward extensions of [23], and novel ideas are introduced in some of the theoretical analyses. Most of the theoretical results are corroborated through computational experiments.
It is to be noted that the state-space-based methods [26–283133] need at least  time. Though a
time. Though a  -learning-based method [34] needs polynomial update time, it seems that an exponential number of repetitions are required to obtain preferable control actions. Our proposed model may be interpreted as a variant of the infinite-horizon control model [31]. However, our developed algorithms are quite different from those in [31]. Though our proposed algorithms are based on [23], the problems to be solved are different from those in [23] and several new ideas are introduced in development of the algorithms. As a related work, Pal et al. studied the problem of generating BNs with a prescribed attractor structure [28]. Though their model has some similarity with our model, applicability of their methods is limited to small size networks.
-learning-based method [34] needs polynomial update time, it seems that an exponential number of repetitions are required to obtain preferable control actions. Our proposed model may be interpreted as a variant of the infinite-horizon control model [31]. However, our developed algorithms are quite different from those in [31]. Though our proposed algorithms are based on [23], the problems to be solved are different from those in [23] and several new ideas are introduced in development of the algorithms. As a related work, Pal et al. studied the problem of generating BNs with a prescribed attractor structure [28]. Though their model has some similarity with our model, applicability of their methods is limited to small size networks.
The organization of the paper is as follows. First, we briefly review BN and then give a formal definition of the problem. Next, we present our proposed algorithms, their theoretical analyses, and the results on computational experiments. Then, we present an approximate but faster heuristic algorithm. Finally, we conclude with future work.
2. Problem of Controlling Singleton Attractors
In this section, we briefly review the Boolean network model, and then formulate the problem explained above. After that we present enumeration-based algorithms and perform theoretical and empirical analyses.
2.1. Boolean Network and Attractor
Let  represent a Boolean network which consists of a set of
represent a Boolean network which consists of a set of  nodes,
nodes,  , and
, and  Boolean functions,
Boolean functions,  . Generally,
. Generally,  and
and  are regarded as genes and a set of regulatory rules of genes, respectively. Let
are regarded as genes and a set of regulatory rules of genes, respectively. Let  denote the state of
denote the state of  at the time step
at the time step  , where
, where  means that the
means that the  th gene is not expressed, and
th gene is not expressed, and  means that it is expressed. The overall expression level of all genes in the BN is represented by
means that it is expressed. The overall expression level of all genes in the BN is represented by  , which is called the gene activity profile (GAP) of the network at time
, which is called the gene activity profile (GAP) of the network at time  . Since
. Since  ranges from
ranges from  to
to  , there are
, there are  possible global states. Regulatory rules of gene states are given as follows:
possible global states. Regulatory rules of gene states are given as follows:

This rule means that the state of gene  at time
at time  depends on the states of
depends on the states of  genes at time
genes at time  , where
, where  is called the indegree of
is called the indegree of  . Furthermore, the maximum indegree of a BN is defined as
. Furthermore, the maximum indegree of a BN is defined as  . The number of genes which are directly influenced by gene
. The number of genes which are directly influenced by gene  is called the outdegree of gene
is called the outdegree of gene  . The states of all genes are changed synchronously according to the corresponding Boolean functions. A consecutive sequence of GAPs (
. The states of all genes are changed synchronously according to the corresponding Boolean functions. A consecutive sequence of GAPs ( ) is called an attractor with period
) is called an attractor with period  if
if  . When
. When  , an attractor is called a singleton attractor. When
, an attractor is called a singleton attractor. When  , it is called a cyclic attractor.
, it is called a cyclic attractor.
An example of a truth table of a BN is shown in Table 1. Every gene  updates its state according to a regulatory rule
updates its state according to a regulatory rule  . Since the state transitions of this BN are as shown in Figure 1, the system will eventually evolve into one of three attractors. Two of them are singleton attractors,
. Since the state transitions of this BN are as shown in Figure 1, the system will eventually evolve into one of three attractors. Two of them are singleton attractors,  and
and  . The other is a cyclic attractor with period 3,
. The other is a cyclic attractor with period 3,  .
.

State transitions of the Boolean network shown in Table 1.
In this paper, we assume that there are two types of nodes in a BN: external nodes and internal nodes. Let  and
and  be external and internal nodes of a BN, respectively. Note that the total number of nodes in a BN is
be external and internal nodes of a BN, respectively. Note that the total number of nodes in a BN is  hereafter. When it is not necessary to distinguish internal and external nodes,
hereafter. When it is not necessary to distinguish internal and external nodes,  are used to specify nodes. Furthermore, let
are used to specify nodes. Furthermore, let  and
and  denote
denote  and
and  , respectively.
, respectively.
Now, we formulate the main problem of this paper.
2.2. Singleton Attractor Controlling Problem (SACP)
-
(i)
Input: a Boolean network which consists of
 external nodes and
external nodes and  internal nodes, and a score function
internal nodes, and a score function  , that is, a function from
, that is, a function from 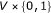 to real. We assume that Boolean functions are randomly assigned to nodes and that the parent nodes of each node are also randomly determined with
to real. We assume that Boolean functions are randomly assigned to nodes and that the parent nodes of each node are also randomly determined with 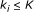 .
. -
(ii)
Output: a 0-1 assignment to external nodes, which maximizes the minimum score of singleton attractors, where the score of an attractor is given as
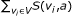 .
.
 external nodes and
external nodes and  internal nodes, and a score function
internal nodes, and a score function  , that is, a function from
, that is, a function from 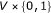 to real. We assume that Boolean functions are randomly assigned to nodes and that the parent nodes of each node are also randomly determined with
to real. We assume that Boolean functions are randomly assigned to nodes and that the parent nodes of each node are also randomly determined with 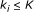 .
.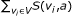 .
.For example, in a BN of Table 1, let  be an external node and let
be an external node and let  and
and  be internal nodes. Furthermore, assume that score functions of nodes of this BN are given as in Table 2. If
be internal nodes. Furthermore, assume that score functions of nodes of this BN are given as in Table 2. If  is fixed as 0, the BN of Table 1 is converted to that shown in Table 3, and its state transition is shown in Figure 2. In this BN, there are three singleton attractors,
is fixed as 0, the BN of Table 1 is converted to that shown in Table 3, and its state transition is shown in Figure 2. In this BN, there are three singleton attractors,  ,
,  , and
, and  , and their scores are
, and their scores are  ,
,  , and
, and  , respectively. Therefore, when
, respectively. Therefore, when  is fixed as 0 in the BN of Table 1, the minimum score of singleton attractors is 6. On the other hand, if
is fixed as 0 in the BN of Table 1, the minimum score of singleton attractors is 6. On the other hand, if  is fixed as 1, the BN of Table 1 is converted to that shown in Table 4, and its state transition is shown in Figure 3. In this BN, there are two singleton attractors,
is fixed as 1, the BN of Table 1 is converted to that shown in Table 4, and its state transition is shown in Figure 3. In this BN, there are two singleton attractors,  and
and  , and their scores are
, and their scores are  and
and  , respectively. Therefore, when
, respectively. Therefore, when  is fixed as 1 in the BN of Table 1, the minimum score of singleton attractors is 7. Thus, in order to maximize the minimum score of singleton attractors, we should fix the external node
is fixed as 1 in the BN of Table 1, the minimum score of singleton attractors is 7. Thus, in order to maximize the minimum score of singleton attractors, we should fix the external node  as 1 since
as 1 since  .
.
 is fixed as 0 in the truth table of Table 1, the following one is obtained.
is fixed as 0 in the truth table of Table 1, the following one is obtained. is fixed as 1 in the truth table of Table 1, the following one is obtained.
is fixed as 1 in the truth table of Table 1, the following one is obtained.
State transitions of the Boolean network shown in Table 3.

State transitions of the Boolean network shown in Table 4.
For this problem, one of the robust algorithms is to enumerate all singleton attractors and check the score of every singleton attractor. For this strategy, it is reasonable to utilize the basic recursive algorithm [23] as a subroutine. Although algorithms proposed in this paper are to some extent similar to those in [23], further observations and different approaches are necessary to estimate their computational time since [23] does not include the notion of external and internal nodes.
3. Enumeration-Based Algorithms
Before presenting enumeration-based algorithms for SACP, we briefly review the basic recursive algorithm in [23]. In this algorithm, partial GAPs are extended one by one towards a complete GAP according to a given gene ordering. If it is found that a partial GAP cannot be extended to a singleton attractor, the next partial GAP is examined. Although all proposed algorithms in this section are based on the same framework which includes the basic recursive algorithm as a subroutine, gene orderings are different from each other. Therefore, we explain only methods of gene ordering for most algorithms although we present the whole pseudocode of the first algorithm.
In what follows, we present algorithms for SACP and estimate their average computational time. Since some approximations are used for these theoretical analyses, each estimated computational time is not exactly the same as the result of the computer experiments shown in Section 3.8.
3.1. Algorithm 1: ExternalAhead
Theoretical Analysis
Assume that  of
of  internal nodes have already been examined. The overall computational time can be represented by
internal nodes have already been examined. The overall computational time can be represented by

The number of terms is  , and each term will be exponential function of
, and each term will be exponential function of  as shown below. The overall average time complexity will only be affected by the largest term in (2) since
as shown below. The overall average time complexity will only be affected by the largest term in (2) since  holds for arbitrary
holds for arbitrary  when
when  and
and  is large enough. Similar discussions will also be applied to the other algorithms.
is large enough. Similar discussions will also be applied to the other algorithms.
For internal nodes, we have

The probability that the algorithm examines the  th gene is not more than
th gene is not more than

The number of recursive calls executed for the first  genes is at most
genes is at most

By setting  , we can obtain
, we can obtain  . Furthermore, we assume that
. Furthermore, we assume that  . Therefore, (5) is rewritten as
. Therefore, (5) is rewritten as

Thus, the average computational time can be estimated as

With simple numerical calculations, we can confirm that the maximum values of (6) for fixed  and
and  are as shown in Tables 5 and 7.
are as shown in Tables 5 and 7.
 .
.3.2. Algorithm 2: Basic
Algorithm for gene ordering. Nodes are chosen at random.
Theoretical Analysis
Assume that  of
of  external nodes and
external nodes and  of
of  internal nodes have already been examined. We can assume that
internal nodes have already been examined. We can assume that  holds approximately. When
holds approximately. When  is large (compared with
is large (compared with  ),
),

The probability that the algorithm examines the  th gene is not more than
th gene is not more than

The number of recursive calls executed for the first  genes is at most
genes is at most

Note that the above term can be ignored when  is small. By setting
is small. By setting  and
and  , the above term can be rewritten as
, the above term can be rewritten as

By setting  ,
,

Similar to the analysis of the previous algorithm, the average computational time can be estimated as  and its maximum values for fixed
and its maximum values for fixed  and
and  are shown in Tables 5 and 7. Note that the range of
are shown in Tables 5 and 7. Note that the range of  is different from that of the previous algorithm.
is different from that of the previous algorithm.
Intuitively, this algorithm is the same as the basic recursive algorithm in [23]. However, the computational time depends on  since
since  always holds for an external node. Therefore, assigning an external node always leads to the next recursive loop, and thus the computational time becomes higher than that of the basic recursive algorithm in [23].
always holds for an external node. Therefore, assigning an external node always leads to the next recursive loop, and thus the computational time becomes higher than that of the basic recursive algorithm in [23].
3.3. Algorithm 3: ExternalBehind
Algorithm for gene ordering. First all internal nodes are examined (Step 1). After that all external nodes are examined (Step 2).
Theoretical Analysis
At Step 1, the number of recursive calls executed for the first  genes is at most
genes is at most

By setting  , we can obtain
, we can obtain  . Note that the definition of
. Note that the definition of  is different from those of the previous algorithms. Therefore,
is different from those of the previous algorithms. Therefore,

Furthermore, by setting  ,
,

At Step 2, the number of recursive calls executed for the first  genes is at most
genes is at most

By setting  ,
,

The whole computational time of ExternalBehind can be bounded by

It can be confirmed that the maximum values for fixed  and
and  are as shown in Tables 5 and 7.
are as shown in Tables 5 and 7.
3.4. Algorithm 4: ExternalLastOne
To achieve smaller time complexity, it is necessary to detect a contradiction for the condition of a singleton attractor at early stage. To detect a contradiction from a node, the node and all its parent nodes must be assigned. Therefore, one of the reasonable methods is to find an assigned node  for which
for which  of
of  parent nodes have already been assigned, and then assign the nonassigned node so that all parent nodes of
parent nodes have already been assigned, and then assign the nonassigned node so that all parent nodes of  are assigned. We call such a nonassigned node LastOne node. In the following three algorithms, we utilize the notion of "LastOne." The frameworks of these three algorithms are the same. (i) First, a nonassigned node is randomly chosen. (ii) Second, if there is a "LastOne" node, assign it either 0 or 1. By further restricting (i) and (ii), we developed the following three algorithms as shown in Table 9.
are assigned. We call such a nonassigned node LastOne node. In the following three algorithms, we utilize the notion of "LastOne." The frameworks of these three algorithms are the same. (i) First, a nonassigned node is randomly chosen. (ii) Second, if there is a "LastOne" node, assign it either 0 or 1. By further restricting (i) and (ii), we developed the following three algorithms as shown in Table 9.
Algorithm for gene ordering. If there is an external node  which satisfies the following condition,
which satisfies the following condition,  is chosen to be assigned either 0 or 1. Otherwise, a nonassigned internal node is randomly chosen.
is chosen to be assigned either 0 or 1. Otherwise, a nonassigned internal node is randomly chosen.  and all parent nodes of
and all parent nodes of have already been assigned except
have already been assigned except .
.
If there are multiple external nodes and both of them satisfy the condition, one of them is randomly selected to be assigned. Moreover, if some external nodes are still nonassigned when all internal nodes have been assigned, remaining nodes will be randomly chosen one by one.
Example 3.1.
Assume that  ,
,  ,
,  , and
, and  have already been assigned either 0 or 1 as shown in Figure 4(a). Furthermore, assume that
have already been assigned either 0 or 1 as shown in Figure 4(a). Furthermore, assume that  is an external node and has not been assigned yet. In such a case, we select
is an external node and has not been assigned yet. In such a case, we select  instead of randomly selecting a nonassigned internal node.
instead of randomly selecting a nonassigned internal node.
For another example, assume that  ,
,  , and
, and  have been assigned as shown in Figure 4(b). Moreover, assume that both
have been assigned as shown in Figure 4(b). Moreover, assume that both  and
and  are nonassigned external nodes. If all internal nodes have already been assigned at this point, one of
are nonassigned external nodes. If all internal nodes have already been assigned at this point, one of  and
and  will randomly be chosen to be assigned and then the other will be assigned. However, such a case rarely happens since
will randomly be chosen to be assigned and then the other will be assigned. However, such a case rarely happens since  is small.
is small.

Example for gene ordering.
Theoretical Analysis
Assume that  of
of  external nodes and
external nodes and  of
of  internal nodes have already been assigned. The average number of edges which are from internal nodes to
internal nodes have already been assigned. The average number of edges which are from internal nodes to  is
is  . The average number of internal nodes of which all parent internal nodes have already been assigned is
. The average number of internal nodes of which all parent internal nodes have already been assigned is

Since the average outdegree of an external node is also  ,
,

holds approximately. Therefore, we have

By setting  and
and  ,
,

holds.
On the other hand,

holds when  is small. Therefore, the probability that ExternalLastOne examines the next internal node of
is small. Therefore, the probability that ExternalLastOne examines the next internal node of  is not more than
is not more than

The number of recursive calls executed for the first  nodes is at most
nodes is at most

by setting  and
and  . From (22) and (25), the computational time of ExternalLastOne can be bounded by
. From (22) and (25), the computational time of ExternalLastOne can be bounded by

It can be confirmed that the maximum values for fixed  and
and  are as shown in Tables 5 and 7.
are as shown in Tables 5 and 7.
3.5. Algorithm 5: LastOneAny
Algorithm for gene ordering. If there is a node  of which all parent nodes have already been assigned except
of which all parent nodes have already been assigned except  ,
,  will be selected to be assigned either 0 or 1. Otherwise, a nonassigned node is randomly chosen to be assigned. If there are multiple nodes and both of which satisfy the above condition, one of them is randomly selected to be assigned.
will be selected to be assigned either 0 or 1. Otherwise, a nonassigned node is randomly chosen to be assigned. If there are multiple nodes and both of which satisfy the above condition, one of them is randomly selected to be assigned.
Example 3.2.
Assume that  ,
,  ,
,  , and
, and  have already been assigned either 0 or 1 as shown in Figure 4(c). Furthermore, assume that
have already been assigned either 0 or 1 as shown in Figure 4(c). Furthermore, assume that  has not been assigned yet. In such a case, we select
has not been assigned yet. In such a case, we select  instead of randomly selecting a nonassigned node. Note that
instead of randomly selecting a nonassigned node. Note that  is not limited to an external node. Moreover, external nodes and internal nodes are not distinguished in this algorithm at all.
is not limited to an external node. Moreover, external nodes and internal nodes are not distinguished in this algorithm at all.
Theoretical Analysis
We have that

holds when  is small. The probability that LastOneAny examines the
is small. The probability that LastOneAny examines the  th gene is not more than
th gene is not more than

The number of recursive calls executed at this step is at most

by setting  ,
,  , and
, and  . Thus, the average computational time can be estimated as
. Thus, the average computational time can be estimated as

With simple numerical calculations, we can confirm that the maximum values of (30) for fixed  and
and  are as shown in Tables 5 and 7.
are as shown in Tables 5 and 7.
3.6. LastOne
Algorithm for gene ordering. If there is a node  which satisfies the following condition,
which satisfies the following condition,  is chosen to be assigned either 0 or 1. Otherwise, a nonassigned internal node is randomly chosen.
is chosen to be assigned either 0 or 1. Otherwise, a nonassigned internal node is randomly chosen.  and all its parent nodes have been assigned except
and all its parent nodes have been assigned except .
.
If there are multiple nodes and both of which satisfy the above condition, one of them is randomly selected to be assigned.
Example 3.3.
Assume that  ,
,  ,
,  , and
, and  have already been assigned either 0 or 1 as shown in Figure 4(d). Furthermore, assume that
have already been assigned either 0 or 1 as shown in Figure 4(d). Furthermore, assume that  has not been assigned yet. In such a case, we select
has not been assigned yet. In such a case, we select  instead of randomly selecting a nonassigned internal node. Note that
instead of randomly selecting a nonassigned internal node. Note that  is not limited to an external node, but external nodes and internal nodes are distinguished when nonassigned nodes are randomly selected.
is not limited to an external node, but external nodes and internal nodes are distinguished when nonassigned nodes are randomly selected.
Theoretical Analysis
Since the average outdegree of an external node is also  ,
,

holds approximately. Therefore, we have

By setting  and
and  ,
,

holds.
On the other hand, the probability that LastOne examines the  th gene is not more than
th gene is not more than

The number of recursive calls executed for the first  genes is at most
genes is at most

by using  . From (33) and (35), the average computational time can be estimated as
. From (33) and (35), the average computational time can be estimated as

With simple numerical calculations, we can confirm that the maximum values of (36) for fixed  and
and  are as shown in Tables 5 and 7.
are as shown in Tables 5 and 7.
3.7. OutdLastOne
In addition to the above algorithms, we tried to find faster algorithms for SACP in terms of empirical time complexity. As a result, the following algorithm yielded the best as shown in Tables 6 and 8, although theoretical analysis has not been performed. This algorithm is the extension of "outdegree-based algorithm" of [23].
 .
. .
. .
.Algorithm for gene ordering. If there is a node  which satisfies the following condition,
which satisfies the following condition,  is chosen to be assigned either 0 or 1. Otherwise, a nonassigned internal node with the highest outdegree is randomly chosen.
is chosen to be assigned either 0 or 1. Otherwise, a nonassigned internal node with the highest outdegree is randomly chosen.  and all its parent nodes have been assigned except
and all its parent nodes have been assigned except .
.
If there are multiple nodes and both of which satisfy the above condition, the one with the highest outdegree is randomly selected to be assigned.
Example 3.4.
Assume that  ,
,  ,
,  , and
, and  have already been assigned either 0 or 1 as shown in Figure 4(d). Furthermore, assume that
have already been assigned either 0 or 1 as shown in Figure 4(d). Furthermore, assume that  has not been assigned yet. In such a case, we select
has not been assigned yet. In such a case, we select  instead of randomly selecting an internal node with the highest outdegree.
instead of randomly selecting an internal node with the highest outdegree.
3.8. Computer Experiments for Enumeration-Based Algorithms
In this section, we evaluate the proposed algorithms by performing computer experiments on random networks, and compare empirical time complexities with theoretical ones. We randomly generated 100 Boolean networks with indegree  , and took the average values. These computational experiments were done on a PC with Xeon 3.6 GHz CPUs and 3 GB RAM under the Linux (version 2.6.16) operating system, where the icc compiler (version 10.1) was used with optimization option-O3-ipo. For each
, and took the average values. These computational experiments were done on a PC with Xeon 3.6 GHz CPUs and 3 GB RAM under the Linux (version 2.6.16) operating system, where the icc compiler (version 10.1) was used with optimization option-O3-ipo. For each  and each
and each  , we plotted 4 or 5 points for each method. For example, Figure 5 shows the experimental result for
, we plotted 4 or 5 points for each method. For example, Figure 5 shows the experimental result for  ,
,  . In the experiment, we randomly generated 100 Boolean networks for
. In the experiment, we randomly generated 100 Boolean networks for  . We used a tool for GNUPLOT to fit the function
. We used a tool for GNUPLOT to fit the function  to the logarithms of the experimental results. The tool uses the nonlinear least-squares (NLLSs) Marquardt-Levenberg algorithm.
to the logarithms of the experimental results. The tool uses the nonlinear least-squares (NLLSs) Marquardt-Levenberg algorithm.

Elapsed time of enumeration-based algorithms for SACP with  and
and  .
.

Base of the empirical time complexities of the enumeration-based algorithms for SACP with  .
.

Base of the empirical time complexities of the enumeration-based algorithms for SACP with  .
.
As a result, empirical time complexities for each algorithm with  and
and  are shown in Tables 6 and 8. Since some approximations are used in the theoretical analyses, the theoretical time complexities shown in Tables 5 and 7 are not exactly the same as those of empirical time complexities shown in Tables 6 and 8. However, magnitude correlations of these algorithms are the same for each
are shown in Tables 6 and 8. Since some approximations are used in the theoretical analyses, the theoretical time complexities shown in Tables 5 and 7 are not exactly the same as those of empirical time complexities shown in Tables 6 and 8. However, magnitude correlations of these algorithms are the same for each  and
and  . Furthermore, differences between theoretical time complexities and empirical time complexities are not very large for each
. Furthermore, differences between theoretical time complexities and empirical time complexities are not very large for each  and
and  . Thus, we can say that our estimation of the theoretical time complexity of each algorithm is relatively appropriate although we used several theoretical approximations to estimate them.
. Thus, we can say that our estimation of the theoretical time complexity of each algorithm is relatively appropriate although we used several theoretical approximations to estimate them.
3.9. Comparison among Proposed Algorithms
As a result of theoretical and empirical analyses for the proposed algorithms for SACP, if  is not large, it is seen that "LastOne
is not large, it is seen that "LastOne  LastOneAny
LastOneAny  ExternalLastOne
ExternalLastOne  ExternalBehind
ExternalBehind  Basic
Basic  ExternalAhead" holds in terms of necessary computational time, where A
ExternalAhead" holds in terms of necessary computational time, where A  B means that A is faster than B. One of the reasonable methods for analyzing the above result is to distinguish these algorithms by depending on whether external nodes or internal nodes are assigned first.
B means that A is faster than B. One of the reasonable methods for analyzing the above result is to distinguish these algorithms by depending on whether external nodes or internal nodes are assigned first.
Let us classify these algorithms into the following three types. (i) First, assign internal nodes. After that assign external nodes. (ii) First, assign external nodes. After that assign internal nodes. (iii) Do not distinguish internal and external nodes. From " ExternalBehind  Basic
Basic  ExternalAhead", it is seen that (i)
ExternalAhead", it is seen that (i)  (iii)
(iii)  (ii) holds for the most basic type of algorithms. Although the other algorithms utilize the notion of "last one," they can also roughly be classified into the above three types. For example, the only difference between "LastOne" and "LastOneAny" is that "LastOne" randomly selects only internal nodes when there are no special nodes, whereas "LastOneAny" randomly selects nodes from both internal and external nodes in the same condition. Therefore, it is reasonable to regard "LastOne" and "LastOneAny" as (i) and (iii), respectively, when comparing these two and we can confirm that (i)
(ii) holds for the most basic type of algorithms. Although the other algorithms utilize the notion of "last one," they can also roughly be classified into the above three types. For example, the only difference between "LastOne" and "LastOneAny" is that "LastOne" randomly selects only internal nodes when there are no special nodes, whereas "LastOneAny" randomly selects nodes from both internal and external nodes in the same condition. Therefore, it is reasonable to regard "LastOne" and "LastOneAny" as (i) and (iii), respectively, when comparing these two and we can confirm that (i)  (iii) holds again. On the other hand, the only difference between "ExternalLastOne" and "LastOne" is that the notion of "last one node" is only applied to external nodes in "ExternalLast," whereas the notion is applied to both internal and external nodes in "LastOne". Therefore, it is also reasonable to regard "ExternalLastOne" and "LastOne" as (ii) and (iii), respectively, in this comparison, and we can confirm that (iii)
(iii) holds again. On the other hand, the only difference between "ExternalLastOne" and "LastOne" is that the notion of "last one node" is only applied to external nodes in "ExternalLast," whereas the notion is applied to both internal and external nodes in "LastOne". Therefore, it is also reasonable to regard "ExternalLastOne" and "LastOne" as (ii) and (iii), respectively, in this comparison, and we can confirm that (iii)  (ii) holds. Note that "LastOne" is classified into (i) in the previous comparison but is classified into (iii) this time. It depends on which two are compared. Thus, we can confirm that (i)
(ii) holds. Note that "LastOne" is classified into (i) in the previous comparison but is classified into (iii) this time. It depends on which two are compared. Thus, we can confirm that (i)  (iii)
(iii)  (ii) holds for various types of comparisons. Intuitively, to reduce the computational time, it is necessary to detect a contradiction for the condition of a singleton attractor at early stage. To detect a contradiction from a node, the node and all its parent nodes must be assigned. However, since
(ii) holds for various types of comparisons. Intuitively, to reduce the computational time, it is necessary to detect a contradiction for the condition of a singleton attractor at early stage. To detect a contradiction from a node, the node and all its parent nodes must be assigned. However, since  always holds for an external node, algorithms cannot detect the contradiction from external nodes. That is why assigning internal nodes first reduces the computational time.
always holds for an external node, algorithms cannot detect the contradiction from external nodes. That is why assigning internal nodes first reduces the computational time.
However, if cyclic attractors are taken into consideration, the above property does not hold. Now, we formulate the extended version of SACP as follows.
ACP : Attractor Controlling Problem
: Attractor Controlling Problem
-
(i)
Input: a Boolean network which consists of
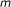 external nodes and
external nodes and  internal nodes, and a score function
internal nodes, and a score function 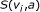 , that is, a function from
, that is, a function from  to real. We assume that Boolean functions are randomly assigned to nodes, and parent nodes of each node are also randomly determined with
to real. We assume that Boolean functions are randomly assigned to nodes, and parent nodes of each node are also randomly determined with 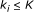 .
. -
(ii)
Output: a 0-1 assignment to external nodes, which maximizes the minimum score of attractors whose periods are
 , where
, where 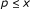 . The score of an attractor is given as
. The score of an attractor is given as 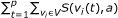 .
.
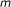 external nodes and
external nodes and  internal nodes, and a score function
internal nodes, and a score function 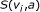 , that is, a function from
, that is, a function from  to real. We assume that Boolean functions are randomly assigned to nodes, and parent nodes of each node are also randomly determined with
to real. We assume that Boolean functions are randomly assigned to nodes, and parent nodes of each node are also randomly determined with 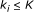 .
. , where
, where 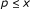 . The score of an attractor is given as
. The score of an attractor is given as 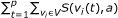 .
.Note that the score of a cyclic attractor is defined as the sum of the score of GAP for each  , but it can be extended to other definitions such as the sum of the minimum score of each node.
, but it can be extended to other definitions such as the sum of the minimum score of each node.
Although our proposed algorithms were introduced for SACP, we extended and implemented them for ACP(2) and ACP(3). A pseudocode of ExternalAhead for ACP is shown in Algorithm 2. Although the main part of each algorithm is the same as that for SACP, the process for checking whether the partial assignments contradict the condition of attractors is different. Let x-ancestor of
is shown in Algorithm 2. Although the main part of each algorithm is the same as that for SACP, the process for checking whether the partial assignments contradict the condition of attractors is different. Let x-ancestor of  be nodes which have a directed path to
be nodes which have a directed path to  with length less than or equal to
with length less than or equal to  . For SACP, algorithms only check the relationship between the assignment of each node and its parent nodes. However, for ACP
. For SACP, algorithms only check the relationship between the assignment of each node and its parent nodes. However, for ACP , algorithms check the relationship between the assignment of each node and its
, algorithms check the relationship between the assignment of each node and its  -ancestors.
-ancestors.
Empirical time complexities for ACP(2) and ACP(3) are shown in Tables 10 and 11, respectively. Since the number of  -
- is relatively large when compared with
is relatively large when compared with  (around 30) for ACP(3), some elements in Table 11 are larger than
(around 30) for ACP(3), some elements in Table 11 are larger than  . Note that these values would be less than
. Note that these values would be less than  if
if  were much larger. It seems that (ii)
were much larger. It seems that (ii)  (iii)
(iii)  (i) holds for
(i) holds for  since "ExternalAhead
since "ExternalAhead  Basic
Basic  ExternalBehind" holds in Tables 10 and 11 although the complexities of "LastOne" and "LastOneAny" are almost the same. It seems that the number of
ExternalBehind" holds in Tables 10 and 11 although the complexities of "LastOne" and "LastOneAny" are almost the same. It seems that the number of  -ancestors affects the empirical time complexities largely. For example, "ExternalAhead" is the slowest for SACP but faster than "Basic" and "ExternalBehind" for ACP(2) and ACP(3). We believe that the reason is that the number of
-ancestors affects the empirical time complexities largely. For example, "ExternalAhead" is the slowest for SACP but faster than "Basic" and "ExternalBehind" for ACP(2) and ACP(3). We believe that the reason is that the number of  -ancestors of assigned nodes for "ExternalAhead" is smaller than that for "Basic" and "ExternalBehind" in the cases of ACP(2) and ACP(3), but it is larger in the case of SACP.
-ancestors of assigned nodes for "ExternalAhead" is smaller than that for "Basic" and "ExternalBehind" in the cases of ACP(2) and ACP(3), but it is larger in the case of SACP.
 .
. .
.Algorithm 1: Algorithm for gene ordering. First, all external nodes are examined. After that all internal nodes are examined.
Pseudocode
Input: Boolean network  and score function
and score function 
Output: 0-1 assignment to external nodes, which maximizes the minimum score of singleton attractors.
Begin
Initialize .
.
For
 to
to
 do
do
For
 to
to
 do
do
 the
the  th digit of the binary number representation of
th digit of the binary number representation of  .
.
Initialize ;
;  .
.
Procedure

If and
and  , then
, then
 ;
;
for to
to do
do ;
;
if it is found that  for some
for some  , then continue;
, then continue;
else ;
;
if and
and  ,
,
then ;
;
for
 to
to
 do
do
 ;
;
if , then return
, then return ;
;
else return null.
End
Algorithm 2: Pseudocode of ExternalAhead for ACP .
.
Input: a Boolean network  and score functions
and score functions 
Output: 0-1 assignments to external nodes, which maximize the minimum score
of attractors whose periods are  , where
, where  . The score of an attractor is given as
. The score of an attractor is given as
 .
.
Begin
Define : nodes which have length-
: nodes which have length- paths to
paths to  .
.
Initialize ;
;
for
 to
to
 do
do
for
 to
to
 do
do
 the
the  th digit of the binary number representation of
th digit of the binary number representation of  .
.
Initialize ;
;  .
.
Procedure

If and
and  , then
, then
 ;
;
for
 to
to
 do
do


for to
to  do
do

while and
and  do
do
if every  is assigned and
is assigned and  then
then


if then continue;
then continue;
else ;
;
if and
and  ,
,
then ;
;
for
 to
to
 do
do

if , then return
, then return ;
;
else return null.
End
3.10. SACP in Scale-Free BN
It is known that gene regulatory networks have the scale-free property; that is, the degree distribution approximately follows the power law [35]. Moreover, it is observed that the outdegree distribution follows the power law and the indegree distribution follows the Poisson distribution [36]. We implemented OutdLastOne for SACP with scale-free networks, where indegrees are 2 and outdegrees are proportional to  . (Note that this
. (Note that this  does not mean indegrees.) The average empirical time complexities of randomly generated 100 BNs are shown in Table 13, and we can confirm that OutdLastOne in scale-free networks is almost as fast as OutdLastOne in random networks examined in Section 3.8.
does not mean indegrees.) The average empirical time complexities of randomly generated 100 BNs are shown in Table 13, and we can confirm that OutdLastOne in scale-free networks is almost as fast as OutdLastOne in random networks examined in Section 3.8.  were used for
were used for  , and similar numbers of nodes were also used for
, and similar numbers of nodes were also used for  .
.
4. Heuristic Algorithms for SACP
In the previous section, we analyzed enumeration-based algorithms for SACP. Although these algorithms are guaranteed to output optimal solutions, it may not be necessary to find the rigorous optimal solutions in some practical cases. One of the possible approaches for this purpose is to use a threshold. Based on it, we develop heuristic algorithms by modifying the original algorithms. In the original algorithms, we update the minimum score whenever a new singleton attractor is found. Instead, in the modified algorithms, we compare the score of a new singleton attractor with a given threshold  and output the corresponding assignment to external nodes as an approximate solution if the score is greater than
and output the corresponding assignment to external nodes as an approximate solution if the score is greater than  . Of course, there may exist multiple attractors for each assignment to external nodes, and the minimum is taken (per assignment to external nodes) in the original algorithms. However, it is known that the expected number of singleton attractors is 1 [3738]. Thus, it is expected that we can obtain a good solution even if we stop the algorithms as soon as a singleton attractor whose score is greater than
. Of course, there may exist multiple attractors for each assignment to external nodes, and the minimum is taken (per assignment to external nodes) in the original algorithms. However, it is known that the expected number of singleton attractors is 1 [3738]. Thus, it is expected that we can obtain a good solution even if we stop the algorithms as soon as a singleton attractor whose score is greater than  is found. How to select
is found. How to select  is also an important issue in these heuristic algorithms. If we know appropriate
is also an important issue in these heuristic algorithms. If we know appropriate  in advance, we can simply use such
in advance, we can simply use such  . Otherwise, we may examine several values of
. Otherwise, we may examine several values of  from lower to upper. For each
from lower to upper. For each  , we manually inspect the solution and we stop further examinations if the solution is satisfactory.
, we manually inspect the solution and we stop further examinations if the solution is satisfactory.
Since there is no performance guarantee on the proposed heuristic approach, we examined it by means of computational experiments. We implemented one of the proposed heuristic algorithms assuming that  is distributed in
is distributed in  uniformly. Furthermore, let us call the following property selectivity: When
uniformly. Furthermore, let us call the following property selectivity: When  is to be assigned, if
is to be assigned, if  holds,
holds,  is examined in advance of examining
is examined in advance of examining  . On the other hand, if
. On the other hand, if  holds,
holds,  is examined in advance of examining
is examined in advance of examining  . Note that the results in Tables 6 and 8 were not with selectivity.
. Note that the results in Tables 6 and 8 were not with selectivity.
Since OutdLastOne was the fastest among our proposed algorithms for SACP, we implemented OutdLastOne with selectivity and  , where
, where  means that a threshold is not used. As a result, empirical time complexities for each
means that a threshold is not used. As a result, empirical time complexities for each  and
and  are obtained as shown in Figure 8 and Table 12, and we can confirm that using a smaller threshold yields better time complexities than using a bigger threshold or not using a threshold. Furthermore, from Tables 14 and 15, it is seen that the average number of singleton attractors in a BN is less than 1 with
are obtained as shown in Figure 8 and Table 12, and we can confirm that using a smaller threshold yields better time complexities than using a bigger threshold or not using a threshold. Furthermore, from Tables 14 and 15, it is seen that the average number of singleton attractors in a BN is less than 1 with  . Therefore, it is reasonable that the proposed algorithm stops as soon as it finds a singleton attractor whose score is greater than
. Therefore, it is reasonable that the proposed algorithm stops as soon as it finds a singleton attractor whose score is greater than  . Tables 14 and 15 also show the average and standard deviations of
. Tables 14 and 15 also show the average and standard deviations of  for each case. It is seen that
for each case. It is seen that  is very close to
is very close to  when
when  . On the other hand,
. On the other hand,  is much smaller than
is much smaller than  when
when  . However, it often occurs that the algorithm cannot find desired singleton attractors when
. However, it often occurs that the algorithm cannot find desired singleton attractors when  . For example, from Table 14, when
. For example, from Table 14, when  ,
,  , and
, and  , it is seen that the algorithm can always find desired singleton attractors if they exist. On the other hand, when the algorithm is applied to 100 random BNs with
, it is seen that the algorithm can always find desired singleton attractors if they exist. On the other hand, when the algorithm is applied to 100 random BNs with  ,
,  ,
,  , it can find desired singleton attractors only for 14 BNs although 64 of 100 BNs include singleton attractors.
, it can find desired singleton attractors only for 14 BNs although 64 of 100 BNs include singleton attractors.
 with
with  and selectivity.
and selectivity. by OutdLastOne for SACP with
by OutdLastOne for SACP with  and selectivity.
and selectivity. by OutdLastOne for SACP with
by OutdLastOne for SACP with  and selectivity.
and selectivity.
Base of the empirical time complexities of OutdLastOne for SACP with  and
and  .
.
We also implemented ExternalAhead with selectivity and a threshold for SACP. As shown in Table 16, empirical time complexities for ExternalAhead were much larger than those of OutdLastOne with  and
and  . It is seen that assigning internal nodes first and utilizing the notion of "LastOne" are also effective for SACP with a threshold.
. It is seen that assigning internal nodes first and utilizing the notion of "LastOne" are also effective for SACP with a threshold.
 with
with  and selectivity.
and selectivity.5. Conclusion
In this paper, we have presented fast algorithms to find a 0-1 assignment for external nodes of a BN, which maximizes the minimum score of singleton attractors. We performed theoretical and experimental analyses for these proposed algorithms, which showed good agreements between their theoretical results and empirical results. It was also suggested that assigning internal nodes in advance of external nodes was the fastest. Furthermore, we have implemented some heuristic algorithms although theoretical analysis has not been performed. One of our future works is to extend our algorithms to a problem where it is not given which nodes are external. Furthermore, for practical use, it is important to develop a method for controlling steady states of a continuous model of biological networks. Although BN is not a continuous model, the idea based on combinatorial models may be utilized in the analysis of continuous models as in [38]. Therefore, it is also our important future work to develop a method for extending our model to continuous one.
References
Kitano H: Computational systems biology. Nature 2002,420(6912):206-210. 10.1038/nature01254
Kitano H: Cancer as a robust system: implications for anticancer therapy. Nature Reviews Cancer 2004,4(3):227-235. 10.1038/nrc1300
Isidori A: Nonlinear Control Systems II. Springer, Berlin, Germany; 1995.
Nijmeijer H, van der Schaft AJ: Nonlinear Dynamical Control Systems. Springer, New York, NY, USA; 1990.
Takahashi K, Yamanaka S: Induction of pluripotent stem cells from mouse embryonic and adult fibroblast cultures by defined factors. Cell 2006,126(4):663-676. 10.1016/j.cell.2006.07.024
Takahashi K, Tanabe K, Ohnuki M, et al.: Induction of pluripotent stem cells from adult human fibroblasts by defined factors. Cell 2007,131(5):861-872. 10.1016/j.cell.2007.11.019
Yu J, Vodyanik MA, Smuga-Otto K, et al.: Induced pluripotent stem cell lines derived from human somatic cells. Science 2007,318(5858):1917-1920. 10.1126/science.1151526
Ching W-K, Ng MM, Fung ES, Akutsu T: On construction of stochastic genetic networks based on gene expression sequences. International Journal of Neural Systems 2005,15(4):297-310. 10.1142/S0129065705000256
de Jong H: Modeling and simulation of genetic regulatory systems: a literature review. Journal of Computational Biology 2002,9(1):67-103. 10.1089/10665270252833208
Smolen P, Baxter DA, Byrne JH: Mathematical modeling of gene networks. Neuron 2000,26(3):567-580. 10.1016/S0896-6273(00)81194-0
Matsuno H, Tanaka Y, Aoshima H, Doi A, Matsui M, Miyano S: Biopathways representation and simulation on hybrid functional Petri net. In Silico Biology 2003,3(3):389-404.
Kauffman SA: Metabolic stability and epigenesis in randomly constructed genetic nets. Journal of Theoretical Biology 1969,22(3):437-467. 10.1016/0022-5193(69)90015-0
Kauffman S: Homeostasis and differentiation in random genetic control networks. Nature 1969,224(5215):177-178. 10.1038/224177a0
Kauffman SA: The Origins of Order: Self-Organization and Selection in Evolution. Oxford University Press, New York, NY, USA; 1993.
Thieffry D, Huerta AM, Pérez-Rueda E, Collado-Vides J: From specific gene regulation to genomic networks: a global analysis of transcriptional regulation in Escherichia coli . BioEssays 1998,20(5):433-440. 10.1002/(SICI)1521-1878(199805)20:5<433::AID-BIES10>3.0.CO;2-2
Huang S: Gene expression profiling, genetic networks, and cellular states: an integrating concept for tumorigenesis and drug discovery. Journal of Molecular Medicine 1999,77(6):469-480. 10.1007/s001099900023
Aldana M: Boolean dynamics of networks with scale-free topology. Physica D 2003,185(1):45-66. 10.1016/S0167-2789(03)00174-X
Drossel B, Mihaljev T, Greil F: Number and length of attractors in a critical Kauffman model with connectivity one. Physical Review Letters 2005,94(8):-4.
Samuelsson B, Troein C: Superpolynomial growth in the number of attractors in Kauffman networks. Physical Review Letters 2003,90(9):-4.
Devloo V, Hansen P, Labbé M: Identification of all steady states in large networks by logical analysis. Bulletin of Mathematical Biology 2003,65(6):1025-1051. 10.1016/S0092-8240(03)00061-2
Garg A, Xenarios I, Mendoza L, DeMicheli G: An efficient method for dynamic analysis of gene regulatory networks and in silico gene perturbation experiments. In Proceedings of the 11th Annual International Conference on Research in Computational Molecular Biology (RECOMB '07), vol. 4453 of Lecture Notes in Computer Science, Oakland, Calif, USA, April 2007. Springer; 62-76.
Irons DJ: Improving the efficiency of attractor cycle identification in Boolean networks. Physica D 2006,217(1):7-21. 10.1016/j.physd.2006.03.006
Zhang S-Q, Hayashida M, Akutsu T, Ching W-K, Ng MK: Algorithms for finding small attractors in Boolean networks. EURASIP Journal on Bioinformatics and Systems Biology 2007, 2007:-13.
Akutsu T, Kuhara S, Maruyama O, Miyano S: A system for identifying genetic networks from gene expression patterns produced by gene disruptions and overexpressions. Genome Informatics 1998, 9: 151-160.
Milano M, Roli A: Solving the satisfiability problem through Boolean networks. Proceedings of the 6th Congress of the Italian Association for Artificial Intelligence on Advances in Artificial Intelligence, vol. 1792 of Lecture Notes in Artificial Intelligence, Bologna, Italy, September 2000 72-83.
Datta A, Choudhary A, Bittner ML, Dougherty ER: External control in Markovian genetic regulatory networks. Machine Learning 2003,52(1-2):169-191.
Datta A, Choudhary A, Bittner ML, Dougherty ER: External control in Markovian genetic regulatory networks: the imperfect information case. Bioinformatics 2004,20(6):924-930. 10.1093/bioinformatics/bth008
Pal R, Ivanov I, Datta A, Bittner ML, Dougherty ER: Generating Boolean networks with a prescribed attractor structure. Bioinformatics 2005,21(21):4021-4025. 10.1093/bioinformatics/bti664
Shmulevich I, Dougherty ER, Kim S, Zhang W: Probabilistic Boolean networks: a rule-based uncertainty model for gene regulatory networks. Bioinformatics 2002,18(2):261-274. 10.1093/bioinformatics/18.2.261
Pal R, Datta A, Bittner ML, Dougherty ER: Intervention in context-sensitive probabilistic Boolean networks. Bioinformatics 2005,21(7):1211-1218. 10.1093/bioinformatics/bti131
Pal R, Datta A, Dougherty ER: Optimal infinite-horizon control for probabilistic Boolean networks. IEEE Transactions on Signal Processing 2006,54(6, part 2):2375-2387.
Akutsu T, Hayashida M, Ching W-K, Ng MK: Control of Boolean networks: hardness results and algorithms for tree structured networks. Journal of Theoretical Biology 2007,244(4):670-679. 10.1016/j.jtbi.2006.09.023
Ng MK, Zhang S-Q, Ching W-K, Akutsu T: A control model for Markovian genetic regulatory networks. Lecture Notes in Computer Science. In Transactions on Computational Systems Biology V. Volume 4070. Springer, Berlin, Germany; 2006:36-48. 10.1007/11790105_4
Faryabi B, Datta A, Dougherty ER: On approximate stochastic control in genetic regulatory networks. IET Systems Biology 2007,1(6):361-368. 10.1049/iet-syb:20070015
Barabási AL, Albert R: Emergence of scaling in random networks. Science 1999,286(5439):509-512. 10.1126/science.286.5439.509
Guelzim N, Bottani S, Bourgine P, Képès F: Topological and causal structure of the yeast transcriptional regulatory network. Nature Genetics 2002,31(1):60-63. 10.1038/ng873
Harvey I, Bossomaier T: Time out of joint: attractors in asynchronous random Boolean networks. In Proceedings of the 4th European Conference on Artificial Life (ECAL '97), Brighton, UK, July 1997. MIT Press; 67-75.
Mochizuki A: An analytical study of the number of steady states in gene regulatory networks. Journal of Theoretical Biology 2005,236(3):291-310. 10.1016/j.jtbi.2005.03.015
Acknowledgments
Wai-Ki Ching supports in part by Research HK RCG Grant no. 7017/07P and HKU CRCG grants.
Author information
Authors and Affiliations
Corresponding author
Rights and permissions
Open Access This is an open access article distributed under the terms of the Creative Commons Attribution Noncommercial License ( https://creativecommons.org/licenses/by-nc/2.0 ), which permits any noncommercial use, distribution, and reproduction in any medium, provided the original author(s) and source are credited.
About this article
Cite this article
Hayashida, M., Tamura, T., Akutsu, T. et al. Algorithms and Complexity Analyses for Control of Singleton Attractors in Boolean Networks. J Bioinform Sys Biology 2008, 521407 (2008). https://doi.org/10.1155/2008/521407
Received:
Revised:
Accepted:
Published:
DOI: https://doi.org/10.1155/2008/521407